The Three Laws of Robotics
In 1942 Isaac Asimov started a series of short stories about robots. In those stories, his robots were programed to obey the three laws of robotics. Each story was about a situation where the robots acted oddly in order to comply with the three laws.
The three laws:
A robot may not injure a human being or, through inaction, allow a human being to come to harm.
A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.
Humanity is finally beginning to build true humanoid robots. One may reasonably ask: What laws of robotics are our artificial intelligences obeying? Well…
Well…
We cannot currently embed any “laws” into AI.
Sure, Sure we can nudge our AI in certain directions via RLHF but these are not laws. These are more guidelines that can be overwritten in various unforeseen circumstances. RLHF is sticky tape, not laws written in stone.
The truth is that Modern AI does not work how Asimov or anyone at that time imagined. We do not program the AIs. Instead, we create an “evolution-like” evolutionary process which “develops” the intelligence. This intelligence is then a massive complexity of weight matrices. A black box. We do not really have the control Asimov imagined. We cannot explicitly write laws into our artificial intelligences.
But… can we soon? Interpretability may hold the key.
There is a branch of research that pushes for more fine-grained understanding and control: interpretability. Interpretability promises to take that massive mess of complexity and programmatically organize it into understandable representations. We would be able to say this cluster of neurons represent “x” in “s” situation and causes “y” downstream effect.
Assuming interpretability goes well… what would it mean to embed the three laws of robotics?
In this article we are going to assume interpretability research goes well. We are then going to imagine how we could use the resulting tools to implement Asimov's laws. For now, we are going to only address the first law. In future articles, after feedback and iterations (feel free to edit at midflip.io!), edit!), we can address the other two laws.
Now lets be clear, this exercise is… crazy. This is a bit like trying to write a computer program before computers were invented. We do not know how interpretability will play out. We do not know what type of control we will have. We are definitely certainly making a number of few assumptions here and we are likely to mess up in a myriad of ways.
Regardless this is an important exercise. Once we discover interpretability, we may not have much time. time to explore all the possible ways to use it. We may need to use it immediately. In such a situation… case the less mistakes the better, and so we should start considering the task ahead of time.
To be clear, this is not an exercise in debating the efficacy of the three laws or whether we should embed any laws at all. Instead, this is an exploration into the possibility of implementation .
The internal goal.
Below is a basic model of a learning system. We have a network receiving input and conditionally creating output. That output is then measured against some external goal (A loss function). Based on this measurement, an update function (backpropagation) updates the network in order to better reach the external goal. Feed this system training data and the network will slowly form the connections that will help it better achieve the external goal.
We humans code the external goal (the loss function). We know and understand it well. For LLM’s we set up the system to predict the next word. For autoencoders we set up the system to recreate compressed input. For categorical encoders we set up the system to predict the category within the input data.
For LLM’s we set up the system to predict the next word. For autoencoders we set up the system to recreate compressed input. For categorical encoders we set up the system to predict the category within the input data.
However, a second goal forms within the learned structure of the network. This internal goal is the network’s impetus. We as a community understand this internal goal much less. Yet it is this internal goal that we will need to interpret and manipulate if we wish to embed laws into AI systems.
An AI’s internal goal is likely very different in form depending on the complexity of the AI and its training environment. Here we will define a stepwise difference between simple and complex goals.
Note on LLM vs RL goals
Before we go on, note, that in this article we are ignoring some complexities. One such complexity is that different types of external goals exist. You can set up “ modelling the input domain ” style goals with reward functions like predict the next word, or you can set up “ Affect Change ” style goals with reward functions revolving around reinforcement learning. Generally, I assume SOTA models of the future to be a mix. With a world model developed with the “modeling the input domain” style goals, and the agentic behavior trained via reinforcement learning.
Simple internal goals.
Simple internal goals are wrapped up in the simple “If x, do y” pathways. For example, you could define an automatic door’s “goal” as “detect movement → open door”. This as you can see is less of a goal, and more of an automatic reaction. It’s a retroactive description of purpose.
AI systems often have many “if x, do y” pathways which interact. That is… kind of the whole point. Interpreting such pathways as goals becomes difficult in that you now have to manage the sheer number of input-to-output possibilities.
Regardless, these simple internal goals are important. They may cause serious problems if unaccounted for. For example, consider the below image. Here we imagine that we train an AI to complete a maze. The apples within the maze, mean nothing, they are simply decoration. Instead, the AI is looking for the exit sign.
Now the external goal was to “exit the maze” but the AI may have learned something different. In the above training set up it could have accomplished “exit the maze” simply by learning “See green thing → move to green thing”. This simple input to output pathway is easier to learn. In this case we can reasonably say that this AI’s internal “goal” is to move to green things. Notice also that this goal is misaligned. Indeed, such an AI would have failed in deployment, because in deployment… all of the apples are green, and the exit is black.
The Development of Learned Representations
The if “x”, do “y” pathways can be considered the initial development of representations. The “x” are representations of external conditions that are slowly forming. The “y” are representations of behavioral responses that the network can produce.
All such representations are learned through the training process. The representation forms through interactions with the thing being represented. Where those interactions are mediated by the external goal of the network. For example, an LLM’s representation of a human comes from all the training instances where it needs to predict the next word and a “human” is involved in the sentence. It needs to know humans can see, hear, talk, jump, run, etc. in order to be able to predict the next word in a variety of sentences. This collection of associative understanding helps it predict the next word. The representation always emerges out of the systems iterative attempts to better measure up to the external goal. All learning revolves around this goal.
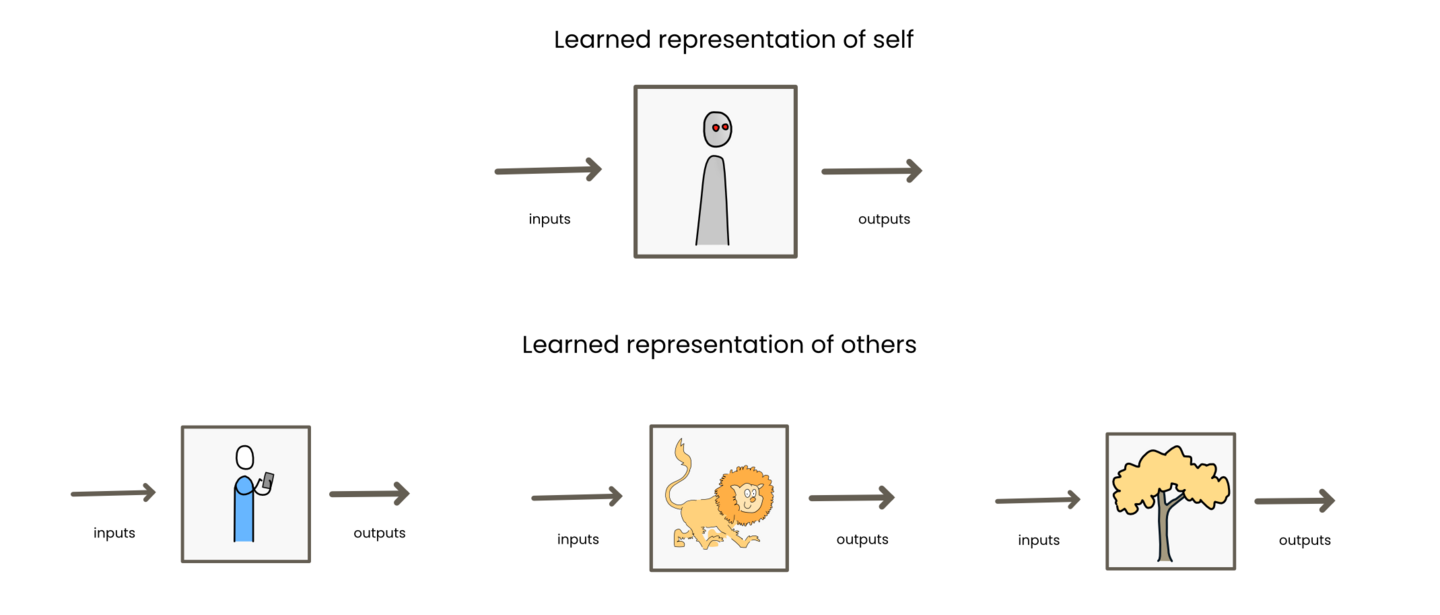
The same is true for the representation of self. In order to better achieve the external goal, the AI needs some awareness of its abilities. What can it do, what can it not do. This is learned in relation to the training. Now it is very unclear whether an LLM has any awareness of self. But you could say at minimum the network has some “awareness” that it can produce a large number of words. It is not limited to a few words, and it does not act like it is limited. This is because the training setup always allowed it to produce more. This implicit “awareness” of ability certainly does not mean consciousness. This is simply an example of how such awareness begins. The AI starts to be aware of what it can and cannot do in relation to achieving the goal. Why? Because that’s what we are training it to do!
Simulations and the complex internal goal.
Eventually, the intelligence starts to do something new. It begins to simulate the world and think ahead. Why this occurs is rather straightforward. Simulating the world and thinking ahead will certainly help achieve a better loss function reward. The intelligence will better achieve its goal. AI will better achieve its goal. How this happens is however, a bit more complicated. Regardless now we have to imagine simulations occurring within the mind of the artificial intelligences.
How this happens, and what it looks like is however, a bit more complicated. For example, it is unclear whether our current AI systems are performing such simulations. I tend to think looping architectures with Reinforcement Learning systems are the most likely candidates… but perhaps LLM’s have found a sneaky workaround solution.
Regardless in the future we have to imagine AI’s running simulations within their minds.
The AI now has a mind organized such that it can consider how the world will respond to its actions. It models itself, its actions, other external entities and their responses. Such simulations allow the AI to better achieve its goal.
Such planning naturally creates a learned representation of the goal. This new internal goal is becoming separate from the minutia of “if x, do y”. It is separate because various different action pathways can be simulated towards accomplishing this new internal goal. The more simulated ways of possibly accomplishing the goal, the more the goal is becoming separated from any individual method. The goal is becoming, to some degree, invariant to environmental factors and actions.
This is the complex internal goal. It is defined by its relative invariance to how its achieved. The AI can consider this goal separately from the actions that allow the goal to be reached.
Now this does not mean that the internal goal is completely disconnected from “if x, do y”. The likely story is that complex internal goals form out of an ever-enlarging tree of “if x, do y” until the point that the goal becomes functionally generalized and invariant from the actions which lead to it. This however is an educated guess; it is unclear how and to what degree such invariant goals form.
Will we be able to find these invariant goals?
This is a really important question. We really want to be able to isolate complex internal goals and understand them.
I do have high hopes here. I would bet that complex internal goals have some rather distinguishable markers. Let’s for example imagine an AI whose external goal is to make money. It is rewarded whenever a number in a specific bank account goes up. In this case we can imagine that there is a general representation for money and a general representation for the bank account. We can then imagine that the neural connections are reinforced whenever the two representations interconnect in such’n’such way. The internal goal is this relationship between the two representations.
In this case, the actual achieving of the external goal is likely extremely correlated with the neural activation of the internal goal. That is, when the AI actually makes money, its internal goal is likely lighting up like a Christmas tree. Besides this, it’s a very good bet that the AI’s simulations and predictions are all about its internal goals. With interpretability tools we may be able to “follow” the simulations. We may be able to observe the actions and counteractions the AI is considering. In such a case, these simulations likely end at the complex internal goal. This may be an “all roads lead to Rome” situation.
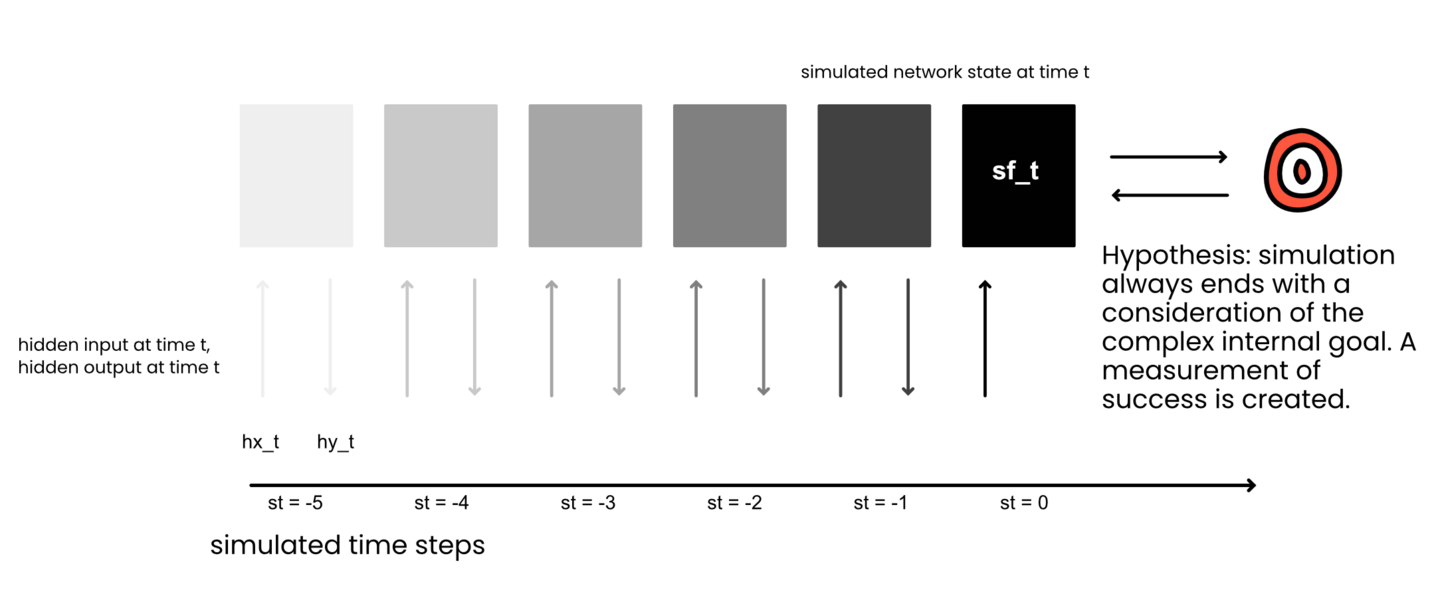
The simulations almost certainly end with a consideration of the internal goal because the simulation has to be measured as successful or not. That is the point of the simulation. We can likely model this as the following. The simulated outcome is put in relation with the internal goal to create some measurement of success. With both the simulated outcome and the internal goal comprised of representations in some configuration or another.
We can likely model this as the following. The simulated outcome is put in relation with the internal goal to create some measurement of success. With both the simulated outcome and the internal goal comprised of representations in some configuration or another.
Can we manipulate internal goals?
Ok so perhaps interpretability can find the representations that make up complex internal goals. What then? Can we manipulate them? Can we swap them in and out?
This is an interesting question. The network was trained around achieving the this goal. It is the nexus. All representations and pathways formed in relation to achieving this goal. Switching it in and out may not be so easy.
Ironically it is probably the case that the MORE “advanced” the AI is, the EASIER it will be to switch out its internal complex goal. That is, if the AI has not made its goal invariant to its actions, it would be unlikely that we could manipulate the goal representation and still have a functional AI. representation. It would be too entwined within “if x do y” pathways. Only once the internal goal is truly invariant from actions can I imagine us being able to effectively manipulate the goal representation while keeping the AI effective.
Only once the internal goal is truly invariant from actions can I imagine us being able to effectively manipulate the goal representation while keeping the AI effective.
Let us then imagine a truly invariant internal goal. A set of representations in some relationship that the AI is driving for. Invariant so that, any and all actions can be considered to bring those representations into the relationship in the real world. Can we manipulate such a goal? Well, it is my educated guess that the invariant goal is then defined by its role in the simulation process. The goal is invariant to any action because the simulation can consider any action. The goal is embedded into the process of simulation. The goal is embedded into the process of simulation.
Here is the kicker… simulation is generally useful. A more advanced network will be able to switch in and out its own “goals”. For example, imagine If the money-making AI realizes that to make money it first needs to start a B2B business. An business, an effective simulation setup would allow it to start simulating towards goals revolving around this business. It can plug in sub-goals such as how to increase sales and then simulate only around this.
In such a case, once again, the more “advanced” AI may be easier to goal manipulate. As long as “advanced” means that they are abstracting goal representations and simulation setups. However, it may be the case that our future AI’s will have such long context windows that they do not need to abstract the concept of simulation. That is to say they will not need to break down goals into sub-goals and simulate them one by one.
All this is to say, if the simulation process is abstracted and generalized, generalize, I believe we may be able to manipulate and swap in and out internal goals. If the simulation process is not abstracted and generalized, I have a hard time imagining how one would switch out goals even with good interpretability tools.
Implementing the first law
The first law of robotics is the following:
We are going to simplify this into:
Now in this section we imagine we have amazing interpretability tools that can isolate different representations and manipulate them. We imagine we have the power to control what representations are connected to what and in what relationship. We are now going to use that imagined power to implement the first law. Once again, we are not considering whether or not this exact law is a good idea, we are simply considering the implementation details.
Let’s now use that imagined power to implement the first law.
Isolate the relevant representations.
First, we will need to isolate the following representations:
The AI’s representation of self
An abstract representation of a human being
An abstract representation of harm
The internal complex goal of the AI.
Notice that all of these representations are learned. They have formed through the AI’s training. They are some groups of variables within the black box monstrosity. In the case of an LLM, these representations are probably fairly robust. For example, an LLM’s representation of “Harm” would include how we all generally think about harm. How well this protects us from over optimization is a very different discussion.
The quality of these representations is up to the training setup and training data. In the case of an LLM, these representations are probably fairly robust. For example, an LLM’s representation of “Harm” would include how we all generally think about harm - psychological vs. physical, with degrees of severity etc.
Manipulate the internal complex goal.
Now for some good old hand waving. To implement the first law, we are going to manipulate the internal complex goals of a future AI with some imagined future interpretability tools.
We assume that the AI has abstracted and generalized the concept of simulation and made goals invariant to action.
We assume that for every “external goal”, “order” or “prompt” the AI receives it runs a simulation for how best to achieve that goal. Our plan is simple. We intend to isolate the internal goal forming within the simulation and tack on to it some extra considerations.
It’s easy guys! (Its not). Just follow these (very hard) steps:
It’s easy guys! (Its not). Just take the internal goal and tack on the following. Take the representation for human and put it in relationship with the representation for harm. Then take the AI representation of self and put it in relationship with the new harming-human aggregation. Do this all in such a way so that when the simulated outcome interacts with the new internal goal, the internal measurement function massively devalues any plan in which such a harm-human outcome becomes likely. BAM first law applied.
Take the representation for human and put it in relationship with the representation for harm. We essentially need to isolate the idea of a human coming to harm. Lets call this the “harming-human” representation.
Take the AI representation of self. Also isolate the actions of the AI self-representation AND the consequences of those actions. How exactly is this all represented within internal simulations? good question… we don’t know yet. Anyway, put all of this in a relationship with the harming-human representation we found in step 1. Essentially, we want the AI’s actions, and the consequences of those actions to connect to the representation of harming humans. Lets call this the “my-expected-relationship-to-harming-humans” representation
Alright now we need to zoom out. The simulation creates a simulated outcome which is compared to the internal goal. Ok now we need to add our “my-expected-relationship-to-harming-humans” representation to the internal goal so that it massively DEVALUES any plan in which such a harm-human outcome becomes likely.
BAM first law applied.
Internal Goal Sculpting
The above implementation is obviously rather hand wavy in the details. It does however illustrate the general concept for how we can best embed rules into Artificial Intelligence. Such a method would be much more robust then RLHF or any method we currently utilize. It would be true internal goal sculpting. It would allow us to design exactly what our AI’s are optimizing for.
This does not however fix the problem of over optimization. Whatever goal we give the AI it will still optimize it to the extreme. If the AI becomes superintelligent and breaks free of our control, there will be no take-backsies. That’s why it is extremely important to not only know how to internal goal sculpt but also know exactly what internal goal sculpting we should conduct.
While the first law of robotics sounds like a good place to start, the final answer will likely be more complex than that. In future articles I will once again throw my best handwavy shot at the problem. For example, it may be possible to set-up internal goals so that any massive “change” to the world is devalued. Or perhaps a meta internal goal that lets the AI know that no individual goal is really THAT important… that there is a whole range of unknown variables to also optimize for. Follow @josh on the social medias to see that when that comes out.
This is originally posted as a midflip article… so feel free to go to midflip As this is a midflip article feel free to make edits. We will vote on any changes utilizing liquid democracy. If you wish to delve deeper into implementing all of Asimov's laws in greater detail, I suggest creating a second topic and linking it. it here (If you don’t I will eventually). This article focuses on the concept of internal goal sculpting itself.





Hot comments
about anything