Attention is all you need." This bold claim in 2017 heralded a new artificial intelligence technique that now powers many of our everyday interactions with technology. From Bing to Google Search to ChatGPT, the transformer architecture is driving major advances in Artificial Intelligence. How exactly do transformers achieve this? The key lies in attention mechanisms.
So lets imagine we have some text data.
Earlier methods based on convolutional or recurrent neural networks would try and processes this data sequentially or spatially. But now we are going to do something different.
First let’s break up this data into tokens. Tokens are numbers that the AI can process, they represent words or sub-words.
Now we will use self-attention layer to model relationships between words or tokens.
In self-attention, each token attends to, or looks at, all other tokens simultaneously. This generates an attention weight distribution over the sequence, indicating the relative importance of every other token to the one currently being processed. This allows capturing dependencies regardless of distance, while attending to the most relevant parts of the input for a given output.
Above is a visual representation of self-attention considering the relative importance of every token relative to the word “I”. An attention layer does this for every word simultaneously. And because everyone uses multi-headed attention layers now, this is done for each word multiple times. This enables learning different types of representations to pay attention to each word.
Query Key Value
How this is implemented gets tricky to explain simply. Below is an image of the mathematical operations to accomplish this.
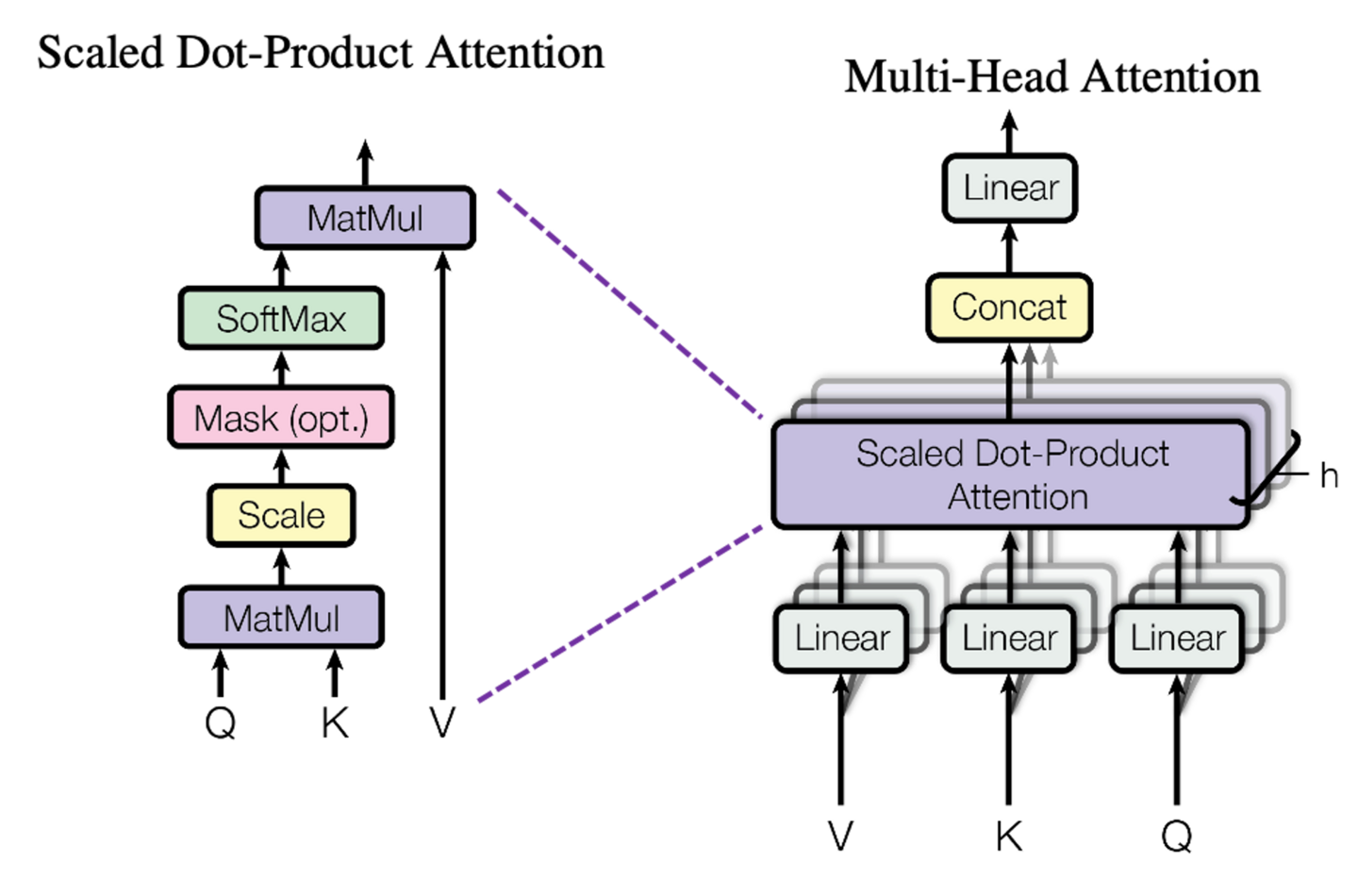
Query (Q): The query is the input that is used to perform attention. It is projected into a query vector representing what we want to focus on or what we want to find relevant information about. For example, if we are translating the sentence "The cat sat on the mat", the query might be the vector representation of the current target word we want to translate.
Key (K): The key vectors are used to help determine relevance or "attention weight" for each part of the value vectors. Keys come from the input sequence, like the source sentence in translation. The key vectors represent possible areas to focus on in determining relevance.
Value (V): The values contain the actual data that will be aggregated based on the attention weights. In seq2seq models, the values generally come from the encoder output. Each value vector represents a specific part of the input, like a word in the source sentence.
During attention, the query is matched against the entire set of key vectors via a compatibility function. This produces scores representing how relevant each part of the values is to this particular query. The scores are normalized into a probability distribution over the values called the attention weights.
The attention context vector is then computed as the weighted sum of the values, with the weights determined by the affinity of their corresponding keys to the current query. This aggregates the parts of the values that were deemed most relevant to the query.
In summary, the query focuses on what's currently needed, the keys help determine relevance, and the values are aggregated based on this query-key relevance to obtain a context vector specific to each query. The interplay between QKV allows attention layers to dynamically pinpoint and summarize relevant information.
Placing Attention layers into the larger Transformer model
Let’s look at the overall transformer architecture:
The transformer has an encoder and decoder structure. Both the encoder and decoder contain multiple identical layers stacked on top of each other. You can think of the encoder as encoding the input text, while the decoder generates the output text.
Within each encoder layer and decoder layer, there are two sublayers: a multi-head attention sublayer and a position-wise feedforward network sublayer.
The multi-head attention sublayer comes first in the sequence. In the encoder, multi-head attention is self-attention where the queries, keys, and values all come from the same place - the output of the previous encoder layer.
In the decoder, one multi-head attention sublayer uses masked attention. The queries come from the previous decoder layer output, but the keys and values come from the output of the encoder stack. This allows the decoder to attend to the encoded input text when needed.
The multi-head attention sublayer output then goes into the feedforward network sublayer, which applies further processing.
Residual (or skip) connections are employed around both the multi-head attention and feedforward sublayers.
-
Layer normalization is also applied before these sublayers. This helps standardize inputs, and helps with training.
Here is a link to where you can play with your own attention-based network





Hot comments
about anything