Abstract
Mathematical models can describe neural network architectures and training environments, however the learned representations that emerge have remained difficult to model. Here we build a new theoretical model of internal representations. We do this via an economic and information theory framing. We distinguish niches of value that representations can fit within.
We utilize a pincer movement of theoretical deductions. First, we build a set of deductions from a top-down model of General Learning Networks. Second, we build a set of deductions from a model based on units of representation. In combination the deductions allow us to infer a “map” of valuable neural network niches.
Our theoretical model is based on measurable dimensions, albeit we simplify these dimensions greatly. It offers a prediction of the general role of a neuron based on its contextual placement and the neuron’s internal structure. Making these predictions practical and measurable requires software that has not yet been developed. Validating our predictions is beyond the scope of this paper.
Top-down direction:
We build the General Learning Network Model based on simple general principles.
We deduce a definition of internal value inherent to all learning networks.
We frame internal representations in information theory terms, which when combined with our general model, results in multiple abstraction metrics depending on the representation of interest.
This allows us to define the “signifier divide” which defines the boundary differentiating different representational domains.
These representational domains allow us to define “top-down” niches of value. Where neural structures within these different representational domains are specialized towards different roles.
Bottom-up direction:
We build the General Representative Inout Model based on simple general principles.
We isolate measurable dimensions in which we can compare the input-to-output mapping of different representational units.
We take these measurable dimensions and consider the extreme poles of these dimensions.
By combining the extreme poles of these measurable dimensions, we define polar archetypical neural structures. These define archetypal types of different neural input-to-output mappings. It is unlikely, your average neuron would display such extreme features, but together these archetypes help define the range of difference.
Based on these polar archetypes we hypothesize specialized functions that fit the form. This gives us “bottom-up” niches of value.
In combination:
We contextualize the bottom-up niches of value within the top-down niches. This results in a series of diagrams that describe where we believe different niches emerge within neural networks.
We describe how our model affects our understanding of symbolic structures, abstraction, and the general learning process.
We highlight the measurable predictions based on the model we have laid out.
1. Introduction
Artificial Intelligence has become popular given the success of large language models such as GPT4. The capabilities of such models are impressive against any measurable test we devise. It is problematic then that our theoretical understanding of such models is questionable. While we understand much, we seem to be missing a key piece.
Mathematically, we can clearly define the network architecture. We can outline the layers, the activation functions, the normalization functions, etc.
Mathematically, we can clearly define the learning environment. We can outline the loss function, the backpropagation algorithm and cleverly mix and match all sorts of different labels.
However, defining the learned structure that emerges is a problem of a different sort. The learned weightings, their interrelations, and the representations they encode are hidden within a wall of complexity. Mathematical attempts to define this learned structure immediately run against this wall. There are simply too many variables and the human mind revolts. While some researchers may have a clever intuition, a clear language has not developed which describes these learned representations.
In this paper, we provide a different approach when addressing learned representations and their interrelations. In summary, we treat the learned structure as an economy of functional forms connecting input to output. We derive an inherent internal definition of value and make a series of deductions relating to the specialization of representations. The result is a set of niches that neural structures fall into. The final model allows us to make predictions about how neurons form, what value they are deriving, and where in the network different representations lie.
Our series of deductions come from two directions and pincer together to create our final model. The first set of deductions originate from a general model of learning networks. The second set of deductions derive from a general model of representational units we call inouts. You can think of inouts as a box that we can scale up and down and move all around a learning network. Wherever this box goes, its contents can be defined as an inout. An inout is an adjustable reference frame within learning networks. Any set of parameters that can produce a learned input-to-output mapping can be defined as an inout. Given this exceedingly general unit we can then describe which reference frames are useful. For example, there are representative units that can exist within neurons so that one neural output can mean different things in different situations [1, 2].
Our top-down deductions allow us to define value inherent to every learning network. In short, the value within a learning network is the efficacy of generating output states in response to input states, as quantitatively assessed by the networks measurement system (the loss function in neural networks). Defining value is important, as the rest of the paper rests on the assumption that neural structures specialize in order to better map inputs to outputs.
We are then able to deduce the signifier divide given an absence of loops. A division that we hypothesize to exist within many input-to-output mappings in learning networks. The signifier divide separates inouts that represent elements within the global input from inouts that represent some behavior within the global output. It divides representations of x from representations of y.
This divide is not exactly a divide. You can still consider neurons representing early input-based patterns (e.g. curve detectors) based on their effect on the network output. However, causation promotes a sometimes discrete, sometimes blurry divide in which representations at the beginning of the network best represent global input variation, and representations at the end of the network best represent global output variation. Given this divide we can describe some broad niches of value. The recognition niche, inouts representing elements within the global input. The response niche, inouts representing elements within the global output. And the prescription niche, inouts that bridge the divide, and connect situational inputs to behavioral responses.
Our bottom-up deductions start by describing sub-neural and neural level inouts. We define a set of hypothetically measurable dimensions which we believe best relate to an inout’s valuable input-to-output mapping. These dimensions are the following. First the relational situational frequency of input channels (whether neural inputs fire together or fire separately in relation with the global input). Second, the neural input relationships with each other with respect to the neural output response (Are the neuron’s inputs complementary, alternatives, inhibitory, stand-alones, etc). And finally, the change in output frequency, defined by taking the average of the inputs situational frequency and comparing that to the neural output’s situational frequency. Many of these measurements require a threshold of significance for both the inputs and outputs of the neuron in question.
You will notice that some of these hypothetically measurable dimensions are themselves multi-dimensional, after all there are multiple inputs into a neuron. Relational situational frequency of inputs and neural input relationship dynamics are in themselves complex affairs. In order to deal with this complexity, we simplify these dimensions dramatically. Future more complex models can be created simply by adjusting how we simplify these dimensions.
We then use an interesting theoretical trick. We take these simplified dimensions and take them to their extremes. We distinguish and define the far poles. We then mix and match these extreme poles to define distinct archetypal neural structures. For example, we can consider a neuron that has inputs which all significantly influence the output, but these inputs all “fire” separately during different input situations, this results in an increasing change of output frequency (We call this particular type of neuron the archetypal trigger structure). Many of these mixed and matched structures are not valuable under any circumstance, but those that are valuable provide us with an interesting trichotomy of neural structures.
The strategy that we just described has many caveats. These archetypal structures are based on the extreme poles of simplified measurements. Let us be extremely clear: real neuronal and sub-neuronal inouts can find a range of in-between structures. Input relationships and situational input frequencies are dimensions of difference which can get far more complicated. The archetypal structures are not meant to convey the reality of what is happening, they instead convey simplified directions of structural variation. This is rather analogous of taking the periodic table and saying the following:
1. Some elements have lots of protons, some have few.
2. Some elements have free electrons allowing for connection points, some do not.
Then we combine these simplified variations to say there are four archetypal polls:
1. Elements with lots of protons and electron-based connection points.
2. Elements with few protons and no electron connection points.
3. Elements with lots of protons and no electron connection points.
4. Elements with few protons and electron-based connection points.
Such a simplification obviously loses a ton of important complexity! Especially in the periodic tables case. However, in the case of deep learning networks, such a simplification is very useful in order to have something to grab on to. In future work, we can slowly add in further complexity so that our understanding becomes more refined.
Given our archetypal structures we begin to hypothesize niches of value that such forms can fill. We then contextualize these niches of value within the top-down framework based around the signifier divide. This provides a general map of sorts, of what representational units are doing where.
Chapter 7, 8, and 9 elaborate on the consequences of our model. In chapter 7, we discuss multi-neural symbolic structures and how continuous and “semi” discrete neural outputs work together to represent elements within relational and contextual structures. In chapter 8, We discuss our new conceptualization of abstraction. Where now within our model, we imagine multiple abstraction metrics depending on the representation we are considering. This chapter also introduces the concept of a micro-signifier divide which certain niches of representative units produce. In chapter 9, we discuss a symbolic growth hypothesis, where we contextualize the growth of different niches within the training process.
Finally, we sum up with chapter 10: measurable predictions. It summarizes our findings on mature input-to-output mappings and reiterates the different niches and how they are useful. It finishes by outlining the set of predictions that our model implies. These predictions are based on our polar archetypes defined by simplified dimensions and so are ‘approximate’ predictions with the caveat that future work can refine such predictions.
Regardless, the general methodology points to a set of measurable predictions. This set of predictions we do not believe are verifiable today, however future work will likely (quickly) be able to create and perform such tests.
We hope that this paper will be a useful building block towards creating interpretable neural network systems. We envision future software solutions which move back and forth finding clues in a sudoku like manner. The combination of these clues we hope will provide decent certainty about what neurons represent what, the value they provide, and how they are interrelated.
As artificial intelligent systems improve in capabilities, certain undesirable future states present themselves. We hope future papers about artificial intelligence include the author’s consideration of externalities and so we present our own brief consideration here. Generally, we believe that there is a danger in a misalignment between what we want and what we measurably optimize towards. This paper is not about optimization techniques, however there is a possible externality that the ideas within this paper will help others improve such techniques. Difficult to tell within the storm of future states whether this would be negative or not. Regardless, we believe that interpretability is necessary if our human civilization is to successfully surf the emerging wave of AI technology. Having the ability to see where you are going and to steer are generally good things when building cars with increasingly powerful engines (safety belts are nice too!).
Finally, before delving into the paper proper, it is pertinent to address a few housekeeping issues. First, it should be noted that this paper is (currently) authored by a single individual. The use of the first-person plural "we" is adopted to maintain the conventional tone of academic discourse. Second, due to author preference, this paper is designed to be read linearly. We address methodological issues and questions within the current context. Finally, the author is engaged in an entrepreneurial venture, building a crowd intelligence website: midflip.io. We aim to innovate how we collaborate. Midflip utilizes king-of-the-hill texts and liquid democracy to iteratively and socially refine topics. A version of this paper is posted to midflip.io as an experimental test case of an academic style paper that updates over time within this system. It is still a young venture, but a very exciting one. You can find these links below and we welcome collaboration.
2. Starting General models
This paper begins by creating a model from the most general, fundamental axioms that are widely accepted as true. While our subject of interest is the learned structure within neural networks, the most general axioms don't specifically apply to neural networks, but to their broader parent class: Learning Networks. Thus, we begin with a big picture, general model of Learning Networks. This will act as our initial top-down general model.
We will then delve into the constitute parts of learning networks and consider general units of representation. Here, however specific idiosyncrasies of neural networks become important, and so we shall describe the nature of neurons themselves, and how these idiosyncrasies relate to the general units of representation. This will create our second bottom-up general model.
Simple assumptions for subsequent discussion
Input-Output mapping – For the purposes of this discussion, we operate under the assumption that Learning Networks establish a functional mapping from input states to output states, guided by a specific measurement function. This excludes odd scenarios such as a network that is always rewarded for producing the number 42, irrespective of input.
Network Training State: Furthermore, we generally assume (unless stated otherwise) that the Learning Networks under consideration are not only trained but are also proficient in mapping inputs to outputs.
General learning network model
A network in its broadest sense is a collection of interrelated entities. For example, the solar system is a network, as each body of mass is affected by the others via their gravity bound relationships. But the solar system is not a learning network. There is no progressive learning that changes the relationships between the bodies of mass.
Learning networks are a set of interrelated entities whose internal makeup is systematically altered to better achieve some goal. To elucidate the concept of learning networks, we employ the INOMU framework. INOMU is an acronym for Input, Network, Output, Measurement, and Update. At a basic level, we can describe each of these as: Network receives input, network processes input, network produces output, output is measured based on some “target” state, and then the network updates based on that measurement. The steps of measurement and update collectively constitute what is commonly referred to as an optimization function. This enables the Learning Network to ‘learn’ and improve its performance over time.
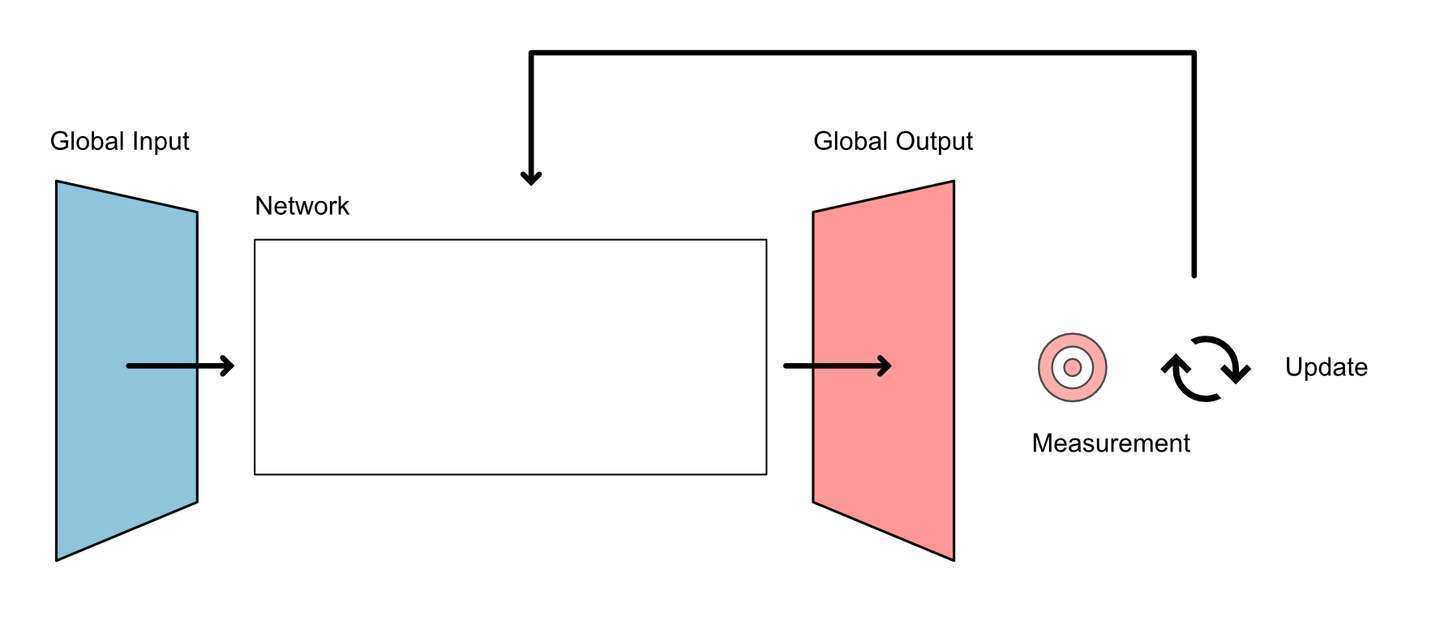
Learning Networks are the parent class in which neural networks belong. Other members of the Learning network class include: the Gene Regulatory Network with evolution as the optimization function, the economy with human demand and design as the optimization function, and the brain with a complex and not fully understood optimization function.
We will refer to the input of the Learning Network as the global input. This is contrast to the input of a neuron of interest, which would have its own local input. The global input is a part of a set of possible inputs: the global input phase space. A multi-dimensional space that encompasses all possible combinations of input variables. The global input phase space is often constrained by the training set. The set of input to output mappings the Learning Network has experienced, resulting in its current capabilities.
The input into a learning network is structured by the shape of sensory apparatuses that “capture” the input. An image-like input, for example, has structured relationships between the pixels, where neighboring pixels are more related in space. This inherent structure in the input we call the input spatial structure. It captures the relationships between the “sensors” which are common among input data.
The global output does not have sensors, it has actuators. It creates change. The global output represents behaviors within whatever domain the network is operating. The global output phase space is then the set of possible behaviors the network can perform. This can then be further constrained by the training set, to represent only those behaviors the network has learned to perform.
Similar to the input, the output from a learning network is structured by the shape of its actuators which “change” the output. For example, a network which produces a sequence of data has outputs which are inherently related in temporal order. This inherent structure in the output we call the output spatial structure.
The learning network should be considered a product of its environment. You cannot consider the learning network without knowing its inputs and outputs. The dimensionality, structure and essence of the input and output should be integral to your conceptualization of any learning network. It is, for example, important to know if the network is generally expanding or compressing information.
The Learning Network itself we consider simply to have unchangeable structural components s, and changeable parameters p which update over training.
F = F(s, p)
Global Input: The data, signals or objects fed into the network for processing.
Network: The core architecture that processes the input. It consists of interconnected modules that perform specific transformations. Consists of structural elements s and changeable parameters p.
Global Output: The result produced by the network after processing the input.
Measurement: A quantitative evaluation of the output against a desired target state.
Update: The adjustment of the network's internal parameters based on the measurement.
Input/Output Phase Space: multi-dimensional space that encompasses all possible combinations of input or output variables.
Training Set: The set of input to output mappings the Learning Network has experienced, resulting in its current capabilities.
General Internal Entities - Inouts
Within learning networks are a set of interrelated entities which adjust and represent. In deep learning we generally consider artificial neurons. However, in this paper we challenge the assumption that the neuron is the best unit of consideration. This paper is specifically interested in representation, and the neuron, we will find, does not best capture the representations formed within deep learning networks.
Instead, we introduce a general computational entity within Learning Networks and call it an 'Inout'.
An "Inout" is defined extremely generally. It is a generic computational entity within a Learning Network. It is a grouping of parameters that takes in input and produces an output. You can think of inouts as a box that we can scale up and down and move all about a learning network. Wherever this box goes, its contents can be defined as an inout. An inout is an adjustable reference frame within learning networks. It’s a set of interrelated parameters which generates an input-to-output mapping.
But this definition of an inout is so general that it has an odd quality. Inouts can nest. Inouts can belong within inouts at different degrees of complexity. Indeed, the entire learning network itself can be defined as an inout. After all the learning network has its own input, output, and adjustable parameters. By this definition, the neural network itself, groups of neurons, layers of neurons, neurons, and even parts of neurons can all be considered inouts. Alternatively, to consider the biological domain, DNA sequences and proteins can be inouts, cells are inouts, organs are inouts, everywhere there are inouts within inouts!
Local Input: The data, signals or objects received by the inout of interest.
Local Output: The result generated by the inout’s interaction with the input based on its internal logic or function.
Structural components: elements within the inout which do not adjust during changing.
Adjustable Parameters: The modifiable elements within the inout that influence its behavior, such as weights in a neuron or coefficients in a mathematical function.
This extremely general definition of an internal unit may seem too general for its own good. But it has a major benefit. It does not assume any given structure to the Learning Network. It does not assume that neurons are a fundamental unit of computation. In fact, it does not assume any fundamental structural unit.
Because Inouts are essentially reference frames that can be scaled up and down and moved all about, it can sometimes get quite confusing to think about them. Some groupings of parameters are more useful to think about than others, but which ones? We will answer that question as we continue.
Below is an image of the main types of inouts that we will consider in this paper.
The following are terms we use when considering different types of inouts.
Neuron of interest – a neuron that we are focusing on.
Inout of interest – an inout that we are focusing on.
Parent inout – An inout that contains the inout of interest.
Child inout – an inout within the inout of interest.
Base inout – Smallest possible inout given the structure of the Learning Network.
Valuable inout – an inout whose nature has been refined by the measurement function.
Sub-neural inout – an inout that lies within a neuron
Neural inout - an inout that encapsulates all of the inputs, parameters, and output of a neuron.
Representative inout – an inout constrained by a single representation. (to be defined better soon)
Divisible inout – A definition of inputs and outputs that has separate divisible pathways within them. We should not define inouts of interest as such.
neural-output-constrained inout – an inout whose output matches the output of a neuron of interest. Generally, the input of such an inout starts at the global input.
neural-input-constrained inout – an inout whose input matches the input of a neuron of interest. Generally, the output of such an inout ends at the global output.
Specific Internal Entities – Neurons
While the general internal entity of an inout is important, it is also important to consider the specific. The structure of artificial neurons plays a pivotal role in the representations they create. This structure can be explained mathematically as follows.
Nodes and Layers: A single neuron i in layer l computes its output ai(l) based on the weighted sum of the outputs from the previous layer, a(l-1), and a bias term bi(l). Formally, this can be expressed as:
Activation Function: This sum zi(l) is transformed by an activation function f to produce ai(l):
Popular activation functions include ReLU, Sigmoid, and Tanh. For most of this paper we assume ReLU.
Let’s focus on what this structure means for representation. We have multiple input channels all possibly conveying a useful signal, we interrelate these input channels given a set of parameters, and we produce a single output channel.
Each channel of information is a number through a nonlinearity. This number can represent many different things in many different ways. It can represent continuous variables and it can somewhat represent discrete variables by utilizing the nonlinearity. We say somewhat because a truly discrete variable cannot be updated along a gradient, which is required for most deep learning update methods. However, despite this, discreteness can be mimicked.
Note: the nonlinearity of neurons is an important factor going forward. Different activation functions can cause different types of nonlinearities. Generally, here, we assume the relu activation function which creates a nonlinearity so that neuronal output can bottom out at zero. This can allow for a more discrete representation and output patterns. Other activation functions create different capabilities and constraints on neurons and so require different interpretations of sub-neuron inouts.
Fundamental units of representation
For a good while it was generally assumed that neurons were the fundamental unit of representation within neural networks. This was a natural assumption given neural networks are made up of… neurons.
However recent studies by Anthropic call this fundamental unit of representation idea into question. They have shown that neural networks can represent more features than they have neurons, sometimes many more. They look at this phenomenon via studying vectors representing layer level outputs. They show that these vectors can have more features than dimensions.
So, a feature can be detected by something smaller than a neuron. Let’s use our new inout definition to show how this may be true. This is actually rather trivial. Consider groupings of inputs and weightings within a neuron that independently activate that neuron within different contexts.
In the above example we imagine two inputs within neuron i, which with their weightings can together cause neuron i to produce an output. In such a situation we have two inputs leading to one output, with two weights and a bias as adjustable parameters. We now are imagining a functional inout smaller than a neuron.
The other inputs and weightings may interfere with this of course! A neuron only has one output signal. But in this case, we are imagining that the inputs a1 and a2 occur independently of other inputs given the situation / global input. In this particular context, a1 and a2 trigger the output alone, and within this particular context, the output is understood in this particular way. In a different context, the output may be understood differently.
For example, let’s imagine a single neuron in a visual model that recognizes both cars and cat legs. This can happen especially in convolutional networks because cars and cat legs would not occur in the same pixel space in the same image. They are contextually isolated. The output of this neuron is understood by other neurons because they too are activated by the input and have contextual knowledge. If other activating neurons around are cat face, body, and tail then the neuron of interest is considered to represent cat legs.
This neuron of interest has multiple inputs, some are situationally connected, and some are situationally separated. These are useful simplifications. Situationally connected inputs are inputs that fire together - they impactfully vary together during the same input situations. Situationally separated input are inputs that fire separately – they impactfully vary during different input situations. We will define this with more rigor later.
This situational separation means that smaller than neural inouts can create meaningful outputs given context. Given situational separation, sub-neuron inouts can have their own unique combination of inputs that trigger a shared output response. Where this shared output response means different things given context.
This situational connection / separation are two poles to explain a dimension of difference. In reality we should consider the situational frequency of inputs. How often an input significantly influences the output of the neuron of interest. Then we should imagine the shared situational frequency between different inputs. It may be useful here to imagine a clustering algorithm that groups inputs which tend to “fire together”.
Situationally connected – Inputs to a neuron of interest that significantly influence the neuronal output at the same time. The inputs ‘fire together’.
Situationally disconnected / situational separation – Inputs to a neuron of interest that do NOT significantly influence the neuronal output at the same time. The inputs ‘fire separately’.
Situational input frequency – A measure of how inputs significantly influence neuronal output in time (i.e. within the dataset).
Output frequency – A measure of how often the neuron of interest produces a significant output.
You will notice that these definitions all require us to define “significant output” or “significantly influence”. This is difficult because different neurons and contexts may define “significance” differently. What a neuronal output represents will affect what we should consider significant. For example, there should be a marked difference between information channels representing discrete vs. continuous representations because the discrete representations likely make use of the non-linearity. Regardless, defining significance requires specific work on specific neurons and is a significant problem.
Sub neural inouts change how we conceptualize representations within a neural network. We can now imagine neurons that have multiple functional representations within them. A single neuron’s output may mean many different things in different contexts – whether continuous or discrete in nature.
In the below visualization, we get creative with space. The y-axis is the activation of the neuron, while the x-axis is an imaginary amalgamation of multiple input spaces. We use bar graphs where each input’s contribution to y output is depicted separately. We consider an average excitatory scenario for each input and weight and gage how such excitatory states work together to cause the neuron to produce output.
In the diagram we pretend we know which inputs tend to fire together within the environment – i.e. are situationally separated. We then note how situationally connected inputs need to work together to cause the neuron to fire. Assuming discrete representations (an assumption we can relax later).
You can see how this visual depiction highlights the relationships between inputs. It is these relationships that define how input representations are combined to create the output representation. To be clear, this and any visualization fails to capture high dimensional space. In reality, each different ranges of global input would create different input contributions towards neural activation.
We can imagine all sorts of different combinations of input. If two inputs need to work together to cause a positive output, we can describe them as complimentary inputs. If one input can be substituted for another and still cause a positive output, we can call those substitute inputs. If one input is required for neuronal output, we can call that a required input. If one input inhibits neuronal output, we can call it an inhibitory input.
Finally, we can consider standalone inputs. A standalone input is an input that alone can activate the output of a neuron within common training set conditions. This would be the smallest, least complex inout we can imagine within a neural network. A base inout. The base inout is the least complex sub-system that still has the qualities of an inout. Complexity here is measured simply, as the number of inputs, outputs, and adjustable parameters. These standalone inputs have one associated input, weight, and bias.
Base inouts with standalone inputs are interesting in their own right but notice that these base inouts are hardly the basis of representational computing. Importantly the sharing of the output and bias with other inouts means that these base inouts are not fully separatable.
When situational separation is NOT connected to a different representation
We could imagine an algorithm going through each neuron in a network and isolating different input combinations that together can cause a positive output. Such an algorithm would find all sub-neuron inout candidates but many of these candidates are likely false flags. We do not want all combinations of inputs that create a positive output. We want the combinations of inputs and ranges of input which actually occur in the training set and consequently are adjusted by the optimization function. We would need to know which inputs are situationally connected.
This hiccup makes measuring and isolating real sub-neuron inouts for interpretability purposes much harder. We need to understand the context in which different inputs fire. We need to know which inouts actually represent input to output mappings that have been refined by the optimization function. The algorithm would need to keep track of input training data and keep track of which input combinations for each neuron are situationally working together to create a positive output.
However, we have a larger problem. Even if we group inputs into situational groupings that does not mean that we should consider the groupings a part of a sub-neuron inout which represents a single thing! Consider for instance the following example.
All the inputs are situationally separated, all the inputs can individually cause the neuron to produce its output. So, should we consider these five sub-neural inputs all producing outputs with different representational meanings? Or perhaps the output of the neuron has one representational meaning and five separate situations “activate” that representational meaning. For example, what if the representational meaning is “produce y behavior” and five different input situations utilize y behavior. In that case, because the output represents the same thing every time, one should consider this a single representative inout – with one single representational meaning and five situational triggers.
This shows that we cannot just define representational inouts based on situational separation. Sometimes situational separation is put to service a single representation.
General Representational Inout Model
Combining our previous discussions of inouts, neurons, and situational separation gives us the General Representational Inout Model.
Inout’s are a flexible reference frame. While you can define inouts via any input to output mapping, we try and define them so that the output matches how representations are stored within the network. This is not easy. A theoretical rule is the following:
A Representational inout is defined by an output which represents a defined set of variation that is differentiated from surrounding variation.
This rule is based on the fundamental definition of representation. To distinguish and partition a part of reality and label it. This distinguishment is not constrained by structural considerations, which is why we have defined inouts as we have.
As we have seen, sub-neural and neural inouts can define a differentiated set of variation. Keep in mind however that larger inouts involving multiple neurons are no exception. For example, we can have large groupings of neurons which together represent the high-dimensional spatial relationships on a chessboard. The output of that grouping is a part of a “defined set of variation that is differentiated from surrounding variation.” They represent a larger relational context.
When it comes to sub-neural and neural inouts we have seen two important rules when it comes to isolating representational inouts.
The situational connectivity of the inputs is an important clue to whether or not neural outputs have multiple distinct representational meanings.
There are circumstances where situationally separated inputs can still be connected to the same representational output meaning.
Practically defining representative inouts is not easy. However, as we continue with this paper, we shall find other clues which will help in this effort. We will explore how to distinguish inouts based on the value they derive from the measurement function. This will provide further clues. In combination we hope these and other clues all together can create a sudoku style situation where an algorithm can jump and hop around a deep learning model and isolate representational meanings.
Summary of our general models.
We now have our general model of learning networks. We have defined learning networks as a set of interrelated units whose internal composition changes to better fulfill some measurement function. We summarize that into INOMU, where the network receives input, network processes input, network produces output, output is measured based on some “target” state, and then the network updates based on that measurement.
We have defined inouts. A computational entity which doubles as a flexible refence frame. An inout takes inputs and produces output and has adjustable parameters and structural features. The whole learning network can be considered an inout, the smallest single parameter input to output mapping can be considered an inout. The inout is an extremely flexible and general concept.
We have defined neurons. The specific internal structural element within neural networks. We noted that neurons have multiple inputs and one output fed through a nonlinearity.
We then found that neurons can have multiple inouts within them, where the neural output means different things depending on the context. We also looked at how different inputs can have different relationships with each other in relation to how they cause the neuronal output to activate. We introduced the concepts of situational separation and situational frequency. Finally, we added the curve ball that some situationally separated inputs are still united under a single representational meaning.
3. Value within a learning network
In this section we make a series of deductions grounded in the general learning network model. Let’s begin.
Deduction 1: Value is inherently defined within a learning network.
A Learning Network ‘learns’ as it iteratively improves its ability to create a better output, given input. Within this system a ‘better’ output is always defined by the measurement system. The measurement system sets the standard for what’s considered ‘good’ within the context of the learning network. Any change that improves the output’s ability to match the target state can be defined as valuable.
Value within a Learning Network = The efficacy of generating output states in response to input states, as quantitatively assessed by the network’s measurement system.
In this context, an "effective" output state is one that aligns closely with the desired target state as determined by the measurement system. The measurement system not only scores but also shapes what counts as an effective output. Within deep learning the measurement system is encapsulated by the loss function.
Before diving into mathematical formalisms, it's crucial to note that this framework is intended to be general. The exact quantification of value would necessitate a deeper examination tailored to each specific measurement system, which lies outside the scope of this discussion.
Let f: X → Y be the function that maps from the global input space to the global output space. This function is parameterized by p, which represents the weights and biases in a neural network, or other changeable parameters in different types of models.
Let M(Y,T) → R be the measurement function that takes an output y ∈ Y and a target t ∈ Tand returns a real-valued score. The goal in optimization is often to maximize this score, although in some contexts like loss functions, the objective may be to minimize it.
Deduction 2: Valuable pathways and the dual-value functionality of inouts
Expanding on the idea of intrinsic value within Learning Networks, we turn our attention to the contributions of individual inouts to this value. Specifically, inouts are valuable to the degree that they help the larger network produce a better output as quantified by the measurement system.
Given our General Model of Learning Networks certain criteria are required for an inout to logically add value to the larger network.
First an inout has to be connected between the global input and the global output. Otherwise, it cannot help conditionally map global input to global output states.
To be connected between global input and global output an inout either has to connect the entire distance itself or it has to be a part of a sequence of interconnecting inouts that link global input to global output. Such a sequence we call a pathway. In deep learning, artificial neurons are organized into layers, and those layers are linked sequentially to connect global input to global output. Pathways are not to be confused with layers. Pathways run perpendicular to layers as to connect global input to global output. They are branching, crisscrossing sequences of causation starting at global input and ending at global output. To be specific, a pathway can be defined via an inout’s neuronal output. As an inout is a scalable reference frame this can include a set of neuronal output. All causational inputs which lead to that set, and all causational outputs which lead from that set can be defined as the pathway. Generally, we would want to define that set so that it matches with some representation of interest.
Given that an inout is connected between global input and global output, to add value an inout also has to use its position and act in a useful manner to the greater network. It must help with the input to output mapping. To do this each inout has to valuably act upon the global input via its local input and produce a local output state that valuably causes a response in the global output. This is subtle. On the input side, the inout must use its local input in a manner that enables valuable recognition of conditions in the global input state. And on the output side, the inout must conditionally produce a signal/transformation that induces valuable change in the global output.
To summarize a valuable inout must:
Be a part of a pathway connecting global input to global output.
The input side has to enable the recognition of conditions in the global input via its local input.
The output side has to conditionally produce a signal/transformation on the global output via its local output.
Inouts that don't meet this criterion would logically be unable to contribute to the network's overall value as defined by the measurement system.
Let XG be the global input of the Learning Network, and xi be the local input of the inout i. Let YG be the global output of the Learning Network, and yi be the local input of the inout i. We can then say that the inout i enables the causational mapping:
xi → yi
And we mathematically express the value of an individual inout as:
This definition of value considers how a change in an individual inouts mapping between global inputs and global output affects the larger network’s mapping, and how that change affects the measurement function. This is not meant to be measured or practical, it is simply a theoretical equation to understand that an inout has value in relation to the overall learning networks measurement function.
Deduction 3: the functional specialization of inouts
The concept of value is deeply entwined with the concept of specialization. Learning Network’s value is defined by their ability to map input-to-output as to best satisfy their measurement function. This creates a diverse and often complex set of demands on the network. To meet such demands, it becomes evident that specialized interconnected inouts are required. A blob of generally useful inouts is simply inconceivable unless the inouts are themselves a complex learning network (like humans). Even then we see empirically that humans specialize.
This phenomenon is not new. In economic and biological learning networks specialization is self-evident, given specific machinery and organs.
In deep learning network specialization has been substantiated in prior research [3, 4, 5, 6, 8, 9, 10, 11, 12]. This is beautifully evidenced by Chris Olah’s work in visual neural network models [8]. They use feature visualizations where they optimize an image to best stimulate a neuron. The resulting images offer clues to the role of the neuron. Given these feature visualizations, Chris Olah’s team-built categories of neurons within the first few layers of these large visual models. Within the first layer they divide neurons into three groupings: Gabor filters, Color contrast, and other.
They then move to the next layer where those first layer patterns are combined so that neurons recognize slightly more complex patterns.
They continue in this manner deeper into the network, identifying many different neurons and the possible features that they are tuned to recognize. This is empirical evidence of specialization within neural networks, where different neurons specialize into recognizing different types of features in the global input.
Why does specialization occur? First note that the optimization process during learning is constantly searching and selecting input to output mappings that improve the measurement function.
Given this, the concept of specialization emerges out of three rules:
-
Redundancy: Duplicate Input to output mappings are redundant and so are generally not valuable. One will outcompete the other by providing more value and become the sole inout in the role being refined by the optimization process. Alternatively, both inouts will specialize into more specific unique positions given more training.
An exception occurs when signals and computations are noisy, duplicate mappings can be valuable to increase robustness. This is common early in a network’s training.
The same functional components applied to different input to output mappings is not considered a duplicate. For example, convolutions apply the same kernel along spatial or temporal dimensions. Each step in this process is a different input to output mapping along those spatial or temporal dimensions. This is not considered redundant as they represent different things along the space and time dimensions.
Position: Inouts capabilities to map input to output is constrained by their position in the network. Their position determines what local inputs they have access to, and where their outputs are sent. In economic terms, position dictates an inouts unique access to “suppliers” of its input and ”buyers” of its output. An inouts position offers a unique opportunity for specialization.
-
Complexity: An inouts level of complexity (measured by the number of adjustable parameters) constrains the complexity of the input to output mapping the inout can perform.
Thus, inouts at the same level of complexity are competing for similarly complex input to output mappings.
Smaller child inouts within a larger parent inout define the value and specialization of the parent inout. In the same way the value and specialization of a factory is defined by the production lines, machines, and people within it.
These three rules are themselves deductions from our general learning network model. All are grounded in the concepts of input to output mappings within an inout within a network. These rules, along with the fact that the optimization process is continually searching and choosing input-to-output mappings that better suit the measurement function, explain why inouts specialize within the general learning network model.
How do we study specialization?
We hope to find niches within learning networks based on inout specialization. However, studying specialization is problematic.
Specializations are input to output mappings that provide certain “types” of value for the measurement function. We can imagine innovating along “directions of value” so that the input-to-output mapping delivers a better measurement. We shall call these “directions of value” niches. By this definition, a car is a specialization within the transportation niche.
Specializations and Niches are nestable and examinable at different reference frames. A factory may be specialized to make t-shirts, a machine may be specialized to spin thread, a worker may be specialized to move the thread to the next machine. Indeed, we can describe the worker and the machine together as a specialized unit for spinning and delivering thread. To examine specialization and niches is to examine a gestalt.
This should remind you of our inout definition. By not assuming a fundamental unit of computation we have given ourselves a unit of inquiry that mirrors niches and specializations. Inouts as an adjustable reference frame can nest and be divided up in a similar manner.
That, however, still leaves us with a difficult problem. How does one best define specific specializations and niches? How does one draw the dividing lines? This is difficult because there is no useful “a priori” solution. We can actually show exactly why that is the case. Consider that we define “specializations” as valuable input-to-output mappings in different “directions of value” (niches).
Valuable input-to-output mappings could describe any valuable grouping of parameters and “direction of value” simply reduces down to the common backpropagation algorithm where each parameter is given a valuable vector of change as defined by the loss function. This means for every definable inout, you can define a vector of valuable change with as many dimensions as there are parameters in the inout. This is not exactly useful. It would be to say that there are as many niches as there are parameters or definable inouts. This is yet another inscrutable black box. There are no clues of how to group these parameters based on this. The dimensionality of the a priori solution is simply too high.
We humans need to build the categories and dividing lines. This is not new. We have been doing this for a long time. It is just that in most domains; our senses can make out differences that we can all point to, and all agree on. For example, the organs within our bodies. Our bodies are interconnected gestalts with no clear dividing lines. However, we can point to organs like the heart and differentiate imaginary dividing lines between the heart and the circulatory network that it is apart of.
We have, in the past, also built dividing lines within more abstract domains. In these cases, we tend to utilize grounded rules and general models. For example, in biology, to divide up the evolutionary tree, we came up with the rule that a species is defined by whether or not two members can reproduce with each other. This rule fails sometimes, for example, with horses and donkeys, and with tigers and lions, but generally it creates good dividing lines that we can usefully utilize.
Top-down vs. bottom-up definitions.
In this paper we utilize two separate methods of defining niches. A top-down and bottom-up approach. Like digging a tunnel from both ends, we meet in the middle and create a more sophisticated and useful model for it.
First, we define broad niches based on our general learning network model. This top-down approach grounds categories and dividing lines within an extremely general model where we can all see and argue over the model’s axioms. This is similar to dividing up of the evolutionary tree based on the “can two members reproduce” rule. Because our General Learning Network Model is so general, we hope that any deduced dividing lines will also be generally applicable.
The second approach for defining niches is based on useful dimensions that we can measure. This bottom-up approach is reminiscent of dividing up the organs of our bodies based on visual features that we can all distinguish. However, when it comes to neural networks no such visual features present themselves. Instead, we have to get creative. We are going to find a set of measurements that we argue best describe different input-to-output mappings within neural and sub-neural inouts. We will then imagine the extreme “poles”, where we take these measurement dimensions to the extreme. Then we shall mix and match these extreme poles until we find combinations that we can deduce are valuable. These valuable extreme pole combinations we define as specialized archetypes. An idealized neural structure which is valuable because of said structure. We can then consider how these archetypal structures are valuable and thus define niches.
4. Top-Down Specializations
In the next three chapters, we begin isolating niches and specializations within neural networks. We define these niches from two directions: top-down and bottom-up.
In this chapter we move top-down and derive niches based on our General Learning Network Model. These will be broad niches that contain within them many other smaller niches. Because these niches are derived from the General Learning Network Model, they should be applicable to all learning networks, not just neural networks.
Deduction 4: Causational Specialization & the signifier divide
Representation is the modelling of external factors. Within our general model of learning networks there are two sources of external factors that can be modelled. First there are external factors presented by the global input, such as sensed phenomena. Second there are external factors that are triggered onto the global output, such as behaviors. All representations within a learning network must originate from the global input or global output, as there is no other source from which to derive these representations within the scope of our model.
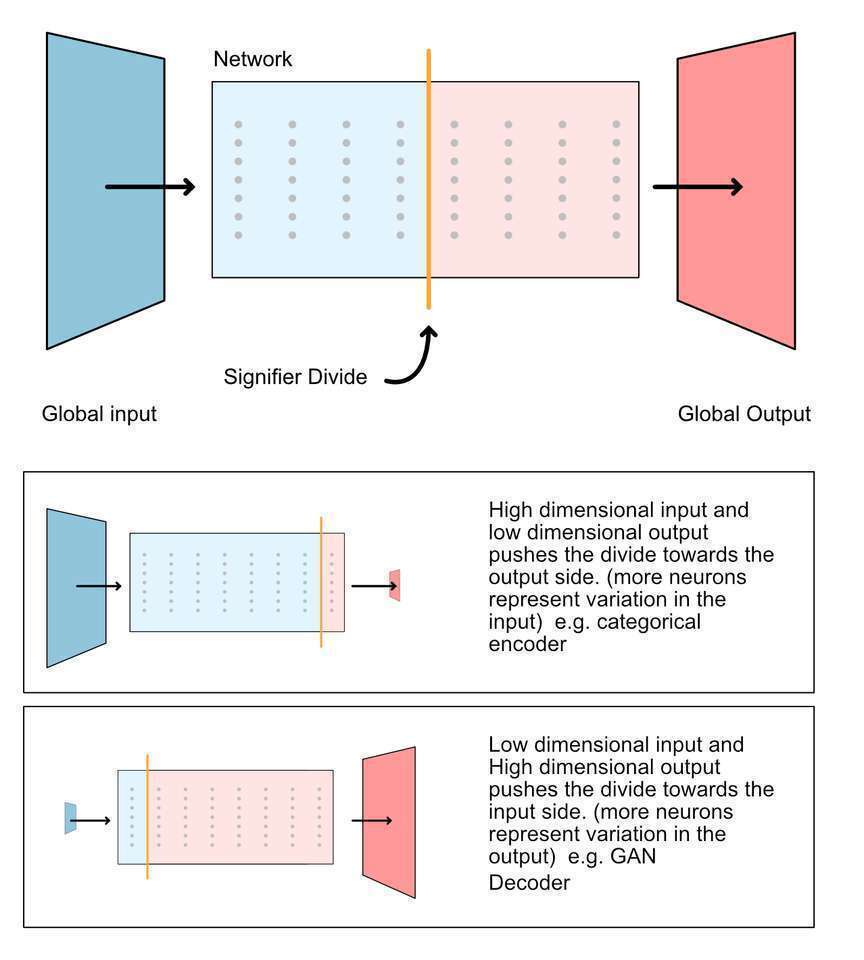
In deduction 4 we claim: Given a trained learning network without loops there is a division s in which representations prior to s are best represented in terms of the global input, and representations after s are best represented in terms of the global output. We call the division s the signifier divide.
This seemingly simple deduction is of outmost importance. It presents a theoretical break from the common knowledge within the deep learning community.
Perhaps this deduction is best understood in information theory terms. Given a trained learning network, there is a division s in which the message conveyed, transitions to a different representational domain. The initial message was based on the input distribution, the final message is based on the output distribution. The signifier divide describes the point of transition.
We will discuss abstraction in much more detail in a future chapter, however for those who already understand. This means there are two distinct types of abstraction.
Input side: Abstraction involves compressing the information contained in the global input into useful features and representations.
Output side: Abstraction involves expanding a different internal representation to construct the desired global output.
The signifier divide marks an imaginary transition point between these two different types of abstraction. It is where we can best say the input situation causationally connects to the produced output behavior.
The signifier divide is not truly a “divide”. Reality is more complicated. For example, the first neurons in a visual neural network often represents curves, or edges or some such low-level input pattern. However, you could technically describe these neurons by their effect on the output of the network. Such an effect would be chaos of causational ‘if’, ‘ands’, and ‘buts’. It would be a meaningless mess of an output representation, but it could theoretically be done. Such initial neurons are better understood by representing input patterns such as curves, because the causational complexity linking the input pattern to the neural output is much (much) less. The representation is more connected to the input side.
The same is true on the output side. We can imagine a visual autoencoder neural network. In such a network, we can imagine a neuron which is linked to the generation of a curve. Whenever the neural output is triggered, the model creates a curve in such-n-such location. Now technically we could describe this neuron based on its input situation. We can list 60000 different input situations where this neuron fires, and say this neuron represents these 60000 different global input situations. But this is rather meaningless, the neuron is causationally closer to the output side. Describing it in input situational terms is a representational domain mismatch.
The signifier divide separates these representational domains. On one side, it is causationally simpler to say: this is based on the global input. On the other side, it is causationally simpler, to say : this represents a behavioral response. Given this context we can still discuss “sharp” aspects of the signifier divide. We can imagine simple robotic toys which have rules like “see big moving things” -> “run-away”. This is a sharp causational connection between a representation based on the input, and a representation based on the output. However, we can also discuss “continuous”, “blurry” aspects of the divide. We can imagine multi-dimensional continuous transformations which slowly change input space to output space.
There are situations in which we consider the divide to be absent. To elaborate, let’s call x* a representational embedding of x. So that x* directly represents some distinguished set of variation within x. The signifier divide is “absent” when y = x* or x = y*.
Consider y = x*, this is when the global output is itself a representational embedding of the global input. This is the case in categorical encoders, where the input is an image, and the output is a classification of the image. In this case, there is no value in y having a separate representational message, y itself is a representation of x.
To consider the other, x = y*. This is when the global input is itself a representation embedding of the global output. This is the case in the generator network within GAN networks. Now the input has no meaning, the GAN generator input is traditionally noise. It is the output where all representational value is derived.
These rules become important when we consider arbitrary inouts. Consider that we can divide the network by isolating inout sections. In such a case, the inout section has its own definable global input to output mapping. Does such a section have its own signifier divide? Well, If we isolate a section of the network on either side of the divide, the divide of the larger network remains within the same spot. The signifier divide of the inout section fills the role x = y* or y = x* and ‘points’ towards the where the larger network divide is. If an inout has an output which is a representative embedding of its input then we can conclude that the signifier divide of the larger network is downstream.
As a general rule, the signifier divide moves depending on the function of the network and the dimensionality of the input and output side. High dimensionality within the input may require more “work” in isolating useful representations and so the divide moves towards the output side.
Justifying the signifier divide – behavioral modularization
Let us now consider a separate intuition. One based on behavioral modularization.
First, we reiterate some of our earlier deductions. Learning networks map inputs to outputs as to deliver a better measurement. This creates an inherent internal definition of value. Functional specialization then occurs as different parts of the network are better suited to different tasks, and given a learning gradient, improve into their specialized role.
Given this, we claim that there is general value in reusing behaviors so that multiple situational inputs can utilize these behaviors. Consider for instance all the situations in which it is valuable to walk. Would it make sense to have all situational inputs linked to their own separate walking output behavior? Or would it be more efficient and effective to have these situational inputs all linked to a single walking module? Obviously, the latter.
During training it is more immediately valuable to make use of what is already available. We argue modularization of output behavior tends to be inevitable given that multiple different input situations find similar behaviors valuable. This of course does not mean that the modularization is optimal and that redundancies do not occur. Real life is messy.
A perfect reuse is not required either. A situational input that requires a slightly different behavior is generally better off utilizing a common behavior and altering it. For example, side stepping an obstacle does not likely utilize an entirely different movement module. It is likely a learned adjustment within the walking module. Creating an entirely new codified behavior requires much more structural changes and should therefore be considered less likely.
The trick here is that the mapping of global input to global output is not uniformly parallel. Where one valuable input leads to one valuable output. Instead ranges of otherwise independent areas of input space can map to similar output behaviors. This is especially true when the dimensionality of the global output is low, whilst the dimensionality of the global input is high.
This is important to the signifier divide for multiple reasons. First, it justifies the idea of neurons representing behaviors. If twenty disconnected situations connect to a neuron that triggers the “run” behavior, is the neuron representing those twenty disconnected situations or the behavior run? Certainly, good programmer naming conventions would call the modular behavior: run. Second, we see true value in modularizing representations of output space distinctly from representations of input space. Distinct output-side representations are valuable in order to be reused and reutilized.
Behavioral modularization offers a clue to where such a divide may lie. The neurons representing the output behavior may be identifiable in that they have multiple situationally disconnected inputs. The neurons representing the output behavior may be identifiable in that they form specialized groupings modulating and adjusting the behaviors within the valuable range. The clue is different input side representations derived from different situations utilizing common output side representations.
Assuming behavioral modularization, we get another interesting information theory perspective to the signifier divide. We will discuss this perspective in much more detail later. But for now for those who can follow along… We can define representational domains based on whether representations are gaining or losing information about the global input or output.
To do this start by imagining the amount of information each representation has about the global input. As representations build on top of each other to make more abstract representations, each representation is gaining more information about the global input. At some point, however, that changes. The point of behavioral modularization along the signifier divide. Past that point, each representation has less information about the global input because multiple input situations can trigger the behavioral response.
This phenomenon is mirrored on the output side. If you consider moving upstream from the global output, each representation will have more information about the global output response than the representation before it. Until you hit signifier divide. At this point each representation starts having decreasing information about the global output response because the input situation has not been fully encoded yet.
What we are seeing here is causational specialization. The representations towards the global output are in a better placement to represent the output. The representations towards the global input are in a better placement to represent the input. We are defining a fundamental rule about Learning Networks based on value.
The value of the representation is the subtle key here. If the value of the representation is derived from the affect it causes it should be considered a “Y*”, a representation of a responsive behavior. If the value of the representation is derived from the situation it recognizes it should be considered a “X*”, a representation of a recognized pattern of inputs. This division is not easy to find, and may not be discrete, however behavior modularization gives us clues.
Contextualizing the signifier divide
Major questions arise from the signifier divide. What is the nature of this divide? Is the divide continuous or discrete? Where in the network is the divide? Is conceptualizing a divide theoretically or practically useful?
These questions do not have simple answers. We shall need to continue further to answer them satisfactorily.
For now, we can provide a simplified model and intuition.
A valuable pathway must connect a valuable recognition of the global input and coordinate a valuable response within the global output. See deduction 2.
If you follow a valuable pathway between input and output, you are guaranteed to cross the signifier divide at some point. See deduction 4.
This includes pathways of different lengths and complexities. Many Learning Networks structures allow for valuable pathways with different lengths. Consider skip-layers in U-Net, or shorter parallelization pathways in the brain. Such pathways will have their own signifier divides as long as they connect global input to output.
The divide can be both sharp and discrete OR continuous and blurry depending on the functions that belie the divide.
If the network has higher global input dimensionality than global output dimensionality then the signifier divide is generally closer to the output side. Indeed, you can set up networks so that there is no effective output side because there is no need to have multiple layers of response. For example, consider categorical encoders, a common deep learning network where the network outputs a category detection such as “Cat” or “dog”. The final output in this case is a representation of the input. In such a network there is no substantial output side.
If the network has higher global output dimensionality than global input dimensionality then the signifier divide is generally closer to the input side. Once again you can set up networks with no effective input side. For example, consider the generator network of GANs, it starts with random noise and eventually produces a “believable” image. There is no substantial input side in this network.
The signifier divide will be of interest for the rest of the paper. We will study how different representational types affect this divide, and if we can isolate it in any meaningful manner.
Representational Niche: Recognition, Prescription, and Response.
We have asserted that if we discount looping information structures, there is a divide in all pathways leading from global input to global output. The divide separates representations derived from the global input and representations derived from the global output. We can use this divide to describe a few broad niches.
First, we have asserted that there is a set of neurons which represent external phenomena either in the global input or global output. We call this broad niche: the representational niche.
Representational niche: Value in representing variation / features within the global input or output.
Within the representational niche we can subdivide neurons into three broad general groupings based on where they lie of the signifier divide. We have termed the following names for these specializations.
Recognition niche – Value in recognizing and representing parts of the global input.
Response niche – Value in representing and altering parts of the global output.
Prescription niche – Value in connecting recognitions on the input side to responses on the output side.
Inouts within the Recognition and Response specialization are defined by their connection to the global input and global output respectively. Inouts within the prescription specialization include functions from both the recognition and response specialization.
You could argue that the prescription specialization is redundant. We could think of inouts that connect input recognitions to output responses as inouts that have dual roles within the representational and Response niches. This is true; however we believe it useful to have a label for such inouts.
Less clear is the nature of these inouts which bridge the gap from recognition to response. Is the transition continuous or discrete? What would it mean for a representation to represent both features within the global input and behavioral responses in the global output?
The Helper niche
The recognition, response, and prescription niche all fit within the representational niche. The representational niche was defined by representing variation or features within the global input or output. A question arises from this. Are there any inouts that do NOT represent variation within the global input or output?
According to our general learning network model all value derives from successfully mapping global input to output and there are no other sources of external variation that affect the network. Any inout providing some other source of value would therefore have to perform some sort of helper function without representing external variation itself.
We could therefore hypothesize about a helper niche. You could argue that this helper specialization should be represented because of empirical evidence. Every learning network, we know about, has niche helper functions. The economy has entire industries that focus on maintaining products that perform valuable functions. Massive portions of the Gene Regulatory Network functionally maintain and preserve the internal conditions that allow for optimal input to output mappings. If these learning networks have helper niches perhaps it is likely that neural networks also have neurons which optimize into helper functions.
We hypothesize that helper functions are universally true within Learning Networks of sufficient complexity because being “helpful” always returns a better measurement score. An assorted array of specializations may act in this capacity, where they do not exactly recognize input or produce output responses, but they generally just make things easier for the inouts which do.
However, defining this niche as 100% separate from the representational niche is likely difficult. Wherever you define helper functions, some representational capacity is generally present. You should think of this niche as exactly that, a niche… a direction of value. A direction of value that acts upon representations without that action relating to the representations themselves.
Some possible examples of the helper specialization within neural networks.
- Noise reduction – Reducing noise or unrelated signals within a channel of information.
- Robustness - value in multiple pathways when one may be compromised.
- Pass along – value in passing along information without any transformation or recognition. This is sometimes valuable as to work around architectural constraints.
These helper specializations are important to consider but are not a core part of the input-to-output mapping process (by definition). Perhaps most notable is the idea that these helper specializations may mess with our identifying of other specialized inouts because they may share similar distinguishing features.
5. Measurable differences relating to neural representation.
“You know there is a sense behind this damn thing, the problem is to extract it with whatever tools and clues you have got.” – Richard Feynmann
Our top-down deductions led us to define the representational niche and the helper niche. Within the representational niche, we took the causational input-to-output mapping of learning networks and split this function into two broad steps. Recognition and response. Additionally, we defined a third niche: the prescription niche, to encapsulate any inouts bridging the gap between recognition and response.
Now we pursue a different direction of distinguishing specializations. Here we distinguish different niches by any means we can measurably identify. We take neural networks and see by which means we can distinguish form and function.
This direction immediately hits a brick wall. The matrices of neural networks seem inscrutable. So how do we proceed?
We will do the following.
Describe a set of measurable differences.
Define extreme poles along those measurable dimensions.
These extreme poles will help us define extreme archetypal solutions.
We can then deduce from the structure of these extreme archetypal solutions how they may or may not be valuable. This will allow us to define niches of value according to measurable dimensions.
This methodology has a few major caveats.
We drastically simplify the set of possible neurons here into a few main groupings. The benefit and curse of this is that it hides a lot of complexity.
The extreme archetypal solutions are architypes, real neurons/inouts may not actually become so specialized in these structural directions. Instead, real neurons/inouts may tend towards being combinations of these architypes.
The choice of measurable differences has a large impact on the final structural demarcations. We have chosen measurable differences that we believe are most relevant. Others may debate for other measurable differences and come to different conclusions.
This methodology requires a deduction step which can be argued over. As with all deductions, it should be clearly stated, and subject to criticism.
The major advantage of this method is that it gives us a direction! With this method we can start dividing up and understanding neural networks inscrutable matrices. With this method, we hope to build a language with which we can consider different groupings of inouts based on their functional role.
Our other objective here is to establish a framework that transitions from theoretical postulates to measurable predictions, thereby paving the way for future empirical investigations. It's important to note that this paper does not conduct empirical measurements but instead aims to set the theoretical groundwork for such endeavors. We encourage teams working on AI alignment or interpretability to consider pursuing this avenue of measurements.
Towards this end, as we discuss these measurable differences, we will suggest a broadly defined software solution that can make these measurements. We briefly outline the processes and measurements we envision this software taking. We do not go into specifics however, as a lot of this work requires iterative improvement with feedback.
To be clear, our theoretical work does not require these measurements to be measurable, only understandable, and clear. We do of course, however, want these measurements to be measurable so that we can make measurable predictions.
Requirements for useful measurements to distinguish specialized neural structures
Each measurement needs to give us information about the input-to-output mapping of a neural inout.
The measurement needs to relate to learned relationships.
Each measurement needs to add new information and cannot be assumed from the other measurements.
These requirements make sense because it is the learned input to output mapping that is valuable to the loss function. It is the learned input to output mapping which specializes. It is the learned input to output mapping which produces representations.
As a counter factual you could imagine considering “how many inputs a sub-neural inout has?” as a measurement. This is superficially useful but because this only relates to the inputs and does not describe the relationship between the inputs and output, it is only of limited help in describing how the inout has specialized.
Preconditions for Effective Measurement
Before delving into the metrics, it's essential to establish the preconditions under which these metrics are valid.
Sufficient Network Training
A Learning Network must be adequately trained to ensure that the connections we intend to measure are genuinely valuable according to the loss function. This precondition is non-negotiable, as it lays the foundation for any subsequent analysis.
Pruning Non-Valuable Connections
To reduce measurement noise and improve the precision of our metrics, we suggest neural pruning. Iterative pruning—alternating between training and pruning phases—may be the most effective approach. This strategy aims to leave us with a network primarily consisting of connections that are valuable to the loss function, thus closely aligning with the assumptions of our General Learning Network Model.
Measuring the situational input frequency
We wish to build up an understanding of which inputs are situationally connected, which inputs are entirely situationally disconnected, and which have different situational frequencies. We want to know when an input’s variation impacts the output of the neuron to a significant degree, and we want to know what other inputs it is collaborating with. In simpler words, for each neuron we want to know which inputs fire together, which inputs fire separately, and which inputs sometimes fire together.
With this data we can group inouts by their shared activation and isolate sub neural inouts. We do this by calculating a situational frequency metric. For each neuron:
Identifying Active Instances of Neurons: Begin by pinpointing every instance within the training dataset where neuron i is considered active. An active state may be defined by the neuron's output surpassing a specified activation threshold, or it might be based on specific characteristics of the neuron's activation function. Either way, we need to establish a threshold t that will be used to determine whether a neurons output is significant. Many neurons will always have significant output.
Input significance: Whether or not an input to a neuron i is significant is determined by the upstream neuron that sends the input information channel. If that upstream neuron can be considered “active” and to have passed its own threshold t, we can consider the input significant. An input directly from the global input is always considered significant.
Calculating Situational Frequency: Define C as the number of instances where input x1 significantly influences neuron i, during a neuron i activation. Let T denote the total count of instances where neuron i is active. The situational frequency for the input can then be computed as:
By performing steps 1, 2, and 3 we end up with a massive amount of data. We could further dig into that data by performing various covariance analyses. This would give us insight for each neuron about how each neuronal input co-occurs with other input activations. However, this level of detail is liable to derail us, therefore we suggest cluster analysis.
Cluster Analysis for Input Grouping: Apply cluster analysis to categorize inputs based on their patterns of activating neuron i. This analysis will help in grouping inputs that tend to trigger the activation of neuron i together, providing insights into the neuron's functional connectivity and input dependencies.
Situational frequency relationships between inputs are exceedingly high dimensional. The range of possibilities is excessive. Different inputs occurring at different rates, some being extremely common, some being extremely rare. Some tending to co-occur, some tending to be antithetical… etc.
This chaos of complexity tends to halt further introspection. However here we are going to get past this wall by excessively oversimplifying. We can take all of this multi-dimensional complexity and simply say input grouping s1 tends to fire together and inputs grouping s2 tends to fire together. The inputs within different groupings do not tend to fire together.
We would structure the cluster analysis so that if the co-occurrence of two inputs are below a threshold they do not get grouped together. This allows for situations where neurons have many situationally connected groupings each with one input! If neurons approach such a situation, we simplify by saying all the inputs tend to be situationally disconnected.
Second, we want to outline the different relationships between the situationally connected inputs for each neuron. These are the same input-relationships we considered in chapter 3. Where some inputs work together to cause activation, some inhibit activation, some are required, some are substitutable, and others can cause the neuron to activate by itself.
For neuron i:
Analyze Situationally Connected Input Groupings: Examine each group of inputs that are situationally connected. This includes inputs that contribute to the neuron's activation under certain conditions, even if their contributions are not consistent across all situations.
Calculating Average Contributions of Inputs: For every input within a situationally connected group, calculate its average contribution to the activation of neuron i. This involves assessing how each input, on average, affects the neuron's output across different instances where the group is relevant. This requires knowledge of both the average input value and the weighting neuron i gives to the input channel.
Determining Relationships Among Situationally Connected Inputs: Utilize the calculated average contributions to understand the interrelationships among the inputs within each situationally connected group. This step aims to elucidate how these inputs collectively influence the activation of neuron i, highlighting potential synergistic or independent contributions within the group.
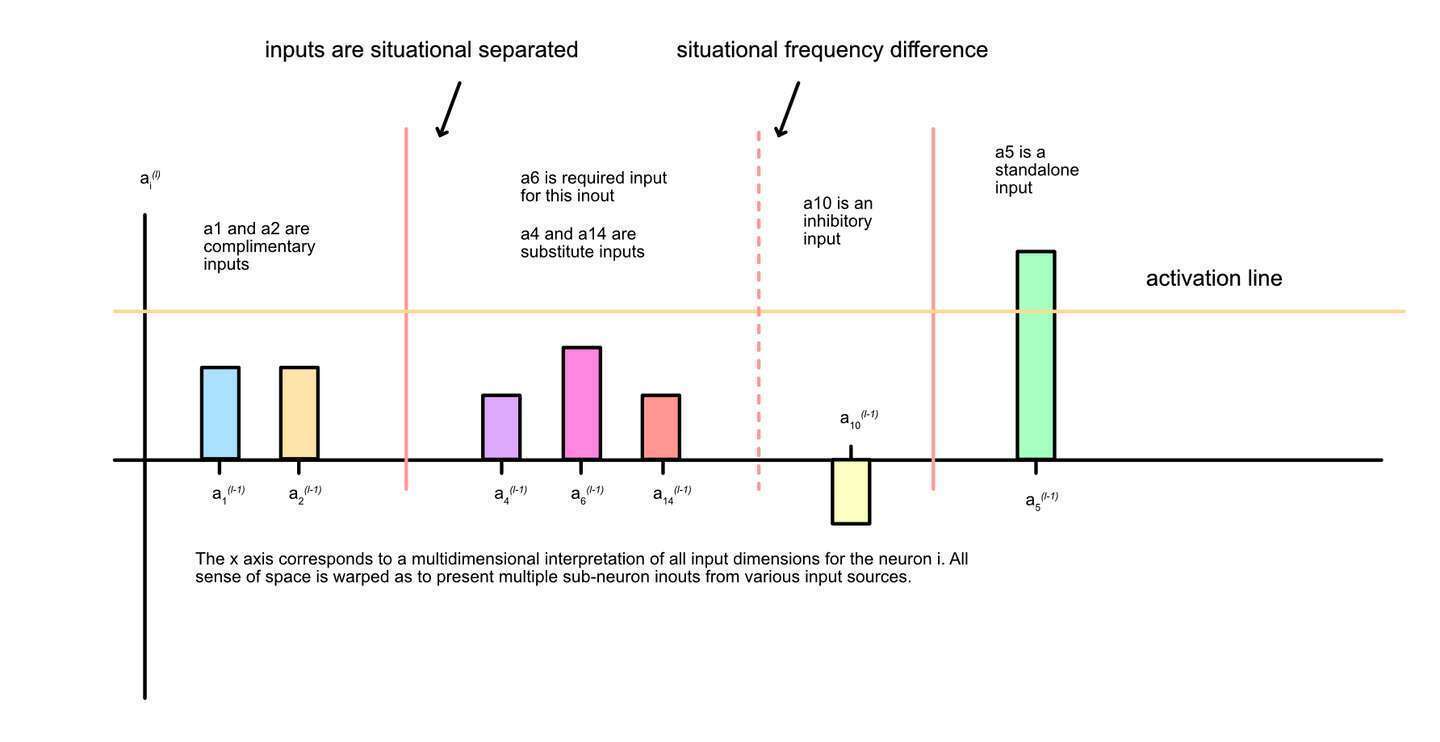
This once again provides a flood of data. There are so many neurons with so many inputs. Considering the relationships between all of them is an immense task. This process threatens to drag us into another black box of complexity. Therefore, at least for our current theoretical work we will make another important simplification.
We will simplify to the following dichotomy. Given a situationally connected grouping of input which produces significant output, does each input have a low individual impact on the neuronal output? Or does each input have a high individual impact on the neuronal output?
This is a drastic simplification. Some inputs negatively vs. positively affect the neuronal output, we are ignoring this. Some inputs have a medium impact on the neuronal output, not too high, not too low. We are ignoring this too. Some, perhaps most, input groupings overlap and form a continuum input landscape that can active neuronal output. We are simplifying this too! We need mass simplification to build a conceptually understandable model. In future work, bringing back some of this complexity will allow us to flesh out the skeletal model we are creating now. Currently, however, we need enforced simplicity to elucidate the complexity.
Finding representative outputs.
We now have a list of situationally connected input groupings for each neuron. We also now know which situationally connected groupings can independently cause significant neuronal output. But this does not mean that these groupings can be considered representative sub-neural inouts.
Perhaps the neuronal output represents the same thing but there are different situational inputs leading to that output. This is likely a common situation. For example, imagine that the neuronal output represents some behavior. There are likely many different situations in which that behavior is valuable. If a neuron had such a setup, we would not describe it as having multiple sub-neural representative inouts, because the neuronal output represents one thing and one thing only. Remember our definition of a representative inout: A Representational inout is defined by an output which represents a defined set of variation that is differentiated from surrounding variation. If these outputs represent the same behavior, they represent the same defined set of output variation.
So how can we differentiate this situation from a situation where different situationally connected input groupings do indeed lead to outputs with different contextual meanings? (and thus be considered a true sub-neural inout). This is potentially difficult and problematic. The major difficulty is that we want to distinguish between outputs with distinct contextual meanings. And we wish to do this based entirely on neural activation patterns. In this section, we suggest a look-ahead strategy combined and validated with a few heuristics.
The idea behind our process is to look ahead to see how neuron i’s output is received by its neighboring downstream neurons. Generally, we want to know whether downstream neurons treat the situationally disconnected output differently depending on the situational context.
For neuron i:
Distinguish situationally connected input groupings within neuron i using cluster analysis as previously discussed. Distinguish which of these situationally connected input groupings cause significant neuronal outputs, as previously discussed. We will consider these s1, s2, s3 etc.
Look ahead to neighboring downstream neurons d1, d2, d3, etc.
Find if neuron i’s activation given situational grouping s1, s2, s3 is consequential in the output of d1, d2, d3, etc.
If a downstream neuron is activated by multiple situational groupings, then we assume the downstream neuron has not distinguished two different contextual meanings. If there were two different contextual meanings, we assume that, given other inputs the downstream neuron would treat the situational groupings as different, and only activate given the presence of one the groupings.
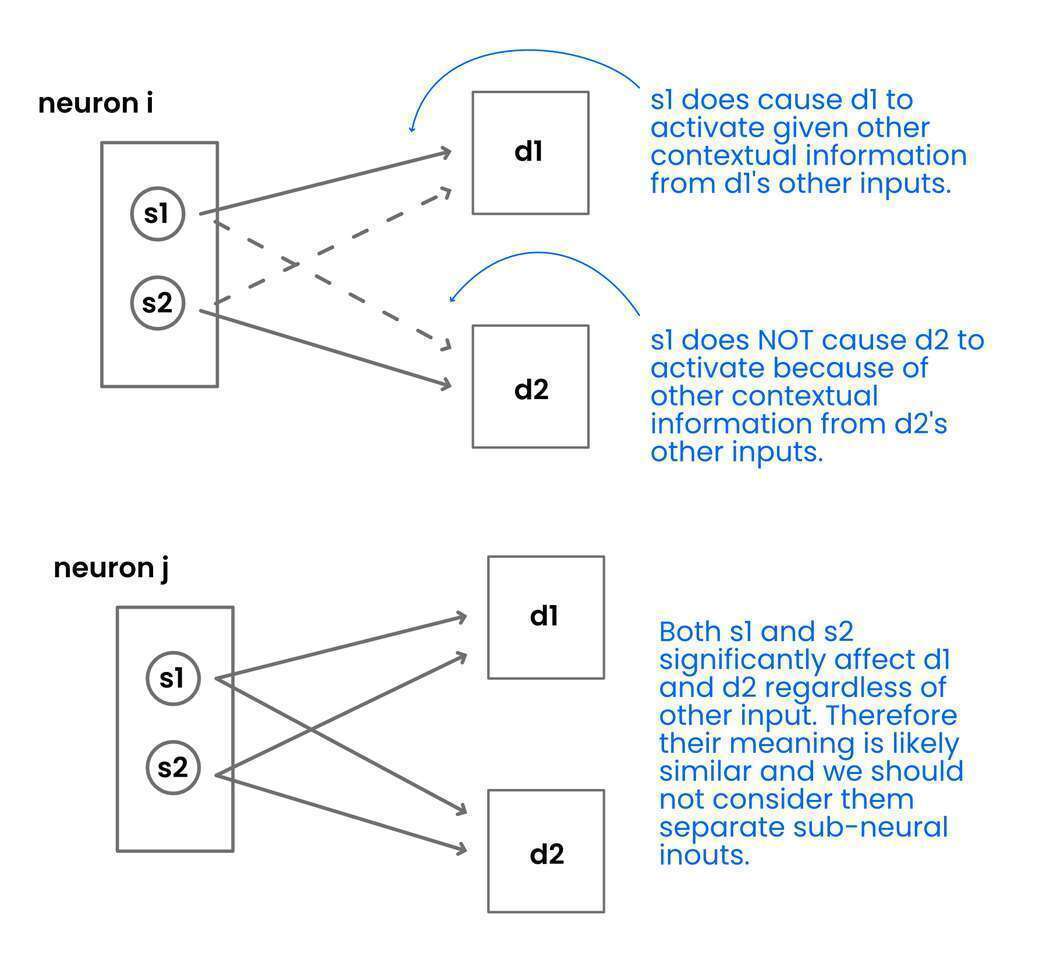
There are two main problems with this method. First, step 4 hides a degree of complexity. It may be tricky to find if neuron i’s s1 vs s2 activation causes different results in different contexts. You may imagine for simplicities sake, d1 having a simple discrete activation in the s1 context, but no activation in the s2 context. However, neurons are often not discrete and rarely that simple. We likely also need to account for instances where the input from s1 is counteracted by another input or inputs with negative weighting given a different context.
The second problem with this method is that contextual differentiation of the situational groupings may occur further downstream. This would mean s1 and s2 are treated the same by d1, but a further downstream neuron has learned to differentiate between the two. We hypothesize (and hope) this is a rare occurrence, however we may be wrong. Attempting to account for contextual differentiation further downstream would drastically increase the search difficulty.
To help cope with these issues we could also employ heuristics based on our modelled understanding of neurons. These heuristics may help us differentiate sub-neural inouts in tricky cases.
We propose that the most promising candidates for distinct representative inouts are characterized by the following features:
-
Combinatorial Nature of Input Groupings: The more complex a situational grouping of inputs which leads to an output, the more likely it has its own distinct representative meaning.
In other words, input groupings that consist of multiple inputs collaboratively influencing the neuron's activation are more likely distinct representative sub-neural inouts. The alternatives are simpler, standalone inputs which trigger the output. In such a case we expect it is more likely that the representative output is the same across different input situations.
Limited Number of Situationally Connected Groupings: Because of 1. We hypothesize that a neuron can incorporate up to two or three situationally connected groupings of input which have distinct contextual meanings. The likelihood of a neuron integrating more than two distinct sub-neural inouts, each with a unique contextual meaning, is considered low, though this requires empirical validation.
Contextual information. We discuss the relevant contextual information in the appendix, utilizing knowledge we have not yet gained.
It is worth mentioning that there are alternate methods to this process. Consider the method suggested by Anthropic: towards monosemanticity [1]. This method would get rid of the difficulty of distinguishing sub-neural inouts. It does this by decomposing representations within neural layers into a new higher dimensional autoencoder. This higher dimensional autoencoder is trained in such a way so that each neuron stores single features. This then sidesteps the sub-neural inout issue. One can also imagine using one method to validate the other.
Measuring change in output frequency
Output frequency is the frequency of significant output from a neural or sub-neural inout. This measurement assumes we have distinguished representative inouts and now considers how often these produce significant output especially in relation to their inputs.
Essentially the process is this:
Isolate representative inouts. (at the sub neural and neural level) (using the methods defined earlier)
Let the network run through the training set.
Count the times that the representative sub-neural inouts and neural inouts are active. "Active" could mean that i's output exceeds a certain activation threshold, or it could be defined based on the neuron's specific activation function.
This count over the number of training set data points is the neural output frequency for each representative sub-neural and neural inout.
If the inout represents some element in the input or behavior in the output, this metric captures the situational frequency of the representational activation within the dataset. The more often a recognition or response occurs the higher the neural output frequency.
Notice that the output frequency of a neighborly upstream neuron is the same as the input frequency in the associated input channel of the neuron of interest. They are measuring the same information channel from two different framings.
While output frequency is interesting it does not fulfill the requirements of being related to the learned input-to-output mapping. What we are actually interested in is the change in output frequency. This is when you compare the output frequency of the neural inout of interest to the average output frequency of its inputs. Whether the output frequency of the neural inout of interest is higher, lower, or the same as the average output frequency of its inputs can tell you a lot about what the neural inout of interest is doing.
The final three measurable dimensions of interest
Our methods of measurement can be summarized as follows.
Isolate situational-connected input groupings.
-
Compare input relationships with the neuronal output.
a. Confirm that situationally connected input groupings can cause significant neuronal output.
b. Find if the inputs within groupings have low vs. high individual impact on the neuronal output. (This hides a large amount of complexity.)
Find sub-neural inouts by seeing whether downstream neurons treat the output of different situationally connected input groupings in a different manner.
Compare the average frequency of input channels providing a significant signal with the output frequency of the neuron of interest.
The above methods of measurements describe our process of exploring learned neural input-to-output mappings. We assume that such a measurement procedure can be performed on neural networks via some future software solution. We assume that the various problems with these measurements can be overcome to an acceptable degree via iterative improvement plus cross validation with other methods. Utilizing our theoretical workings will likely require this. Validating our theoretical predictions will likely require this.
Via the above process we isolated three measurements of specific interest. These three measurements fit our requirements as useful measurements to distinguish specialized neural structures. They described the dimensions of difference between different input-to-output mappings. However, due to the nature of neural representation these measurements were too high dimensional and complex. In order to compensate for this and allow us to make a more understandable model, we simplify these metrics.
For a sub-neural / neural inout with a distinct output meaning the following metrics describe the input-to-output relationship.
Situational connectivity / frequency of the inputs – Which inputs are situationally connected / disconnected? Which inputs are working together in time to affect the output.
Simplified dichotomy:
The relationships between inputs in relation to the neuronal output – How exactly are these inputs working together to cause the output? Are the different inputs exciting vs. inhibiting activation? Are they required / substitutable? Can the input independently activate by itself?
Simplified dichotomy:
3. The neural inouts change in output frequency – Are the inputs on average more or less “active” than the inout’s output over the training set.
Simplified Trichotomy:
The neuronal output has a higher output frequency than its inputs.
The neuronal output has the same output frequency as its inputs.
The neuronal output has a lower output frequency than its inputs.
Each of these massively simplified possibilities are extreme poles along our three measurable dimensions of interest. These extreme poles hide a lot of complexity. This complexity will need to be added back in to create a complete understanding of neural structures. However, for now we stick with these extreme poles. Like a child using training wheels, we use these extreme poles to learn the basics of this representational realm.
In the next chapter we will consider how we can combine these extreme poles to describe different neural structures. The form of these neural structures will then inform on their possible function, allowing us to describe different niches of value neural inouts can fit in.
6. Bottom-up specializations
In the last chapter, we described a procedure to take a series of measurements. This procedure isolated sub-neural inouts with outputs with different meanings. For each meaningful sub-neural and neural inout the procedure also isolated three measurable dimensions of interest. Some of these measurable dimensions, the situational frequency of input and the input relationships, are exceedingly high dimensional. In order to simplify and codify our understanding we simplified these measurable dimensions and identified extreme pole.
-
The situational frequency of its inputs
-
The relationships of inputs in relation to the inout’s neural output.
-
The inout’s change in output frequency.
The neuronal output has a higher output frequency than its inputs.
The neuronal output has the same output frequency as its inputs.
The neuronal output has a lower output frequency than its inputs.
Extreme pole combinations
Let’s now consider combinations of these extreme poles. In combination these dimensions describe neural forms that we can fit to function.
Many combinations of our extreme poles are nonsensical because our measurable dimensions are interrelated. These are combinations of features that would never occur together or would never allow the neuron to ever fire. For example:
Situationally disconnected inputs where each individual input has a high impact on the neuronal output will never create a diminishing change in output frequency.
High shared situational frequency where each individual input has low impact on the neuronal output would never create an increasing change in output frequency.
Having situationally disconnected inputs all with weak influence over neural output breaks the neuron. It would never fire in this circumstance.
Having filtered out the nonsensical structures, the extreme poles give us with four structures. We have given names and designed symbols to represent each structure. These are related to the deduced function of the forms and will become important in future notation. We simply introduce them here, in order to give our reader ample time to learn them.
Archetypal fluid structure 1
Inputs are situationally connected.
Inputs are generally low in influence.
Change in output frequency is constant. (The neuronal output is significant at the same frequency of its inputs. This means despite the general low influence of the inputs, the inputs are consistently effecting significant output and the nonlinearity is not being utilized as a discrete cut off)
Archetypal fluid structure 2
Inputs are situationally connected.
Inputs are generally high in influence.
Change in output frequency is constant. (The neuronal output is significant at the same frequency of its inputs.)
Archetypal detection structure
Inputs are situationally connected.
Inputs are generally low in influence.
Change in output frequency decreases. (The neuronal output is significant at a lower frequency of its inputs.)
Archetypal trigger structure
Inputs are situationally disconnected.
Inputs are generally strong in influence.
Change in output frequency increases. (The neuronal output is significant at a lower frequency of its inputs.)
These archetypal structures are based on the extreme poles of simplified measurements. Let us be extremely clear, real neuronal and sub-neuronal inouts can find a range of in-between structures. Input relationships and situational input frequencies can get far more complicated. The archetypal structures are not meant to convey the reality of what is happening, they instead convey simplified directions of structural variation.
How are these archetypal structures valuable?
Consider the set of possible solutions for travel from point a to point b. I am sure you can come up with many. Walking, bike riding, driving, flying, etc. This transportation niche (and most niches we deal with in our lives) are within exceedingly high dimensional and complex domains. We can come up with many varied solutions.
However, when we consider neural and sub-neural inouts, the domain is not nearly as high dimensional. There is a set number of ways inputs can be situationally connected and there is a set number of ways a mathematical neuron can be configured. True, this set is still massive and difficult for us humans to work with but compared to the structures within our economy… there are much less. We can consider this set of structures and how the variations belie different valuable roles.
Certain structures are better at certain things because of how they are structured. Form belies function. So, while our archetypal structures are not niches themselves, they indicate functions which fill niches. By studying these structures, we can hypothesize how they may be valuable. We can say “this structure looks good for doing x”. We are like anatomists first opening up the body, ripping out the heart and saying “well this thing looks like it pumps all that blood stuff around”.
These hypotheses about valuable function are just that… hypotheses. However, we have grounded them considerably. We can now point to the structure which we think fulfills the niche, we can explain why we think it fills this niche, we can contextualize these niches based on the signifier divide, and we can relate the niche to the final measurement function. Best of all, we are also moving towards a point where we can validate these hypotheses. This is because these structures are based on measurable dimensions albeit through a much-simplified lens.
So let us explore these different identifiable archetypal structures and deduce the situations where they are valuable. As these are hypotheses, feel free to disagree and throw your shoe at me (with good arguments).
Requirements to be considered a niche derived from archetypal structure:
We must be able to describe the value added clearly so that others can disagree with the deduction.
The value added must be connected to the form of the archetypical structure. Given input, how does the archetypal structure deliver the uniquely valuable output?
The value must be connected to the input-to-output mapping. For example, “representing a continuous variable” is not a niche we consider because it is stagnant. “Transforming a continuous variable” works because it speaks to the input-to-output mapping process the structure performs.
The value added cannot be specific to certain training sets. For example, “The detector structure can fill the niche of recognizing eyes.” While this may be true, we must stay abstract and generally applicable. Otherwise, the set of potential niches is too large to be useful. Relaxing this constraint in specific cases may be a valuable exercise for the reader.
Caveats:
Niches can nest. There are likely smaller niches within these broader niches that we can define in another way.
The divide between these specializations is not necessarily discrete or clean. It's important to note that inouts may have dual roles. So, it is possible to have inouts that lie on a spectrum between these various specializations.
Sometimes these structures can valuably do the same thing. One may be better, however it is harder to form. Etc.
We expect to have missed niches that others may deduce. We welcome suggestions here.
Archetypal Fluid Structure 1 & 2
We labelled two of the archetypical structure’s “fluid”. This is because given structural similarities, we believe they have very similar functional roles.
The first structure has inputs that are situationally connected and low in influence. The second structure has inputs that are situationally connected and high in influence. Both tend to have a constant change in output frequency. Meaning that the rate of significant variation in the input channels is the same as the rate of significant variation in the output channel.
This means for both structures that whenever the inputs are affecting the neural inout in any way, the inout sends some sort of significant output. As inputs change, the output changes describing some useful continual mapping. However, during all of this, the nonlinearity is not utilized. This is evidenced by the constant change in output frequency. Together this all suggests an output with a continuous meaning.
First let’s imagine a fluid structure working individually. This would be compressing continuous input variables and extracting and representing some individual continuous variable. This can often be useful because the more compressed and selected continuous variable may be a better signal to trigger behavioral output changes. Do not consider such compression random, it is more like a selective consideration of what is important to the measurement function.
Continuous compression niche – Value in compressing continuous variables into a selected form.
While this can happen individually, when it comes to the fluid structure, we should generally imagine large groupings of these structures working together. In combination these structures can do much more.
For example, in combination, the fluid structures can also decompress continuous variables. With more interconnected fluid structures in the downstream layer decompression can occur. Decompression can be valuable for multiple reasons. Perhaps the command to perform a behavior needs to be conveys to a large number of actuators acting in the global output. This is a valuable decompression to match the output space. Alternatively, decompression can be valuable when two information streams interact and combinatorial consequences need to be valuably modelled.
Continuous decompression niche – Value in decompressing continuous variables into a selected form.
Most prototypically, fluid structures work together in large groupings to represent high dimensional data. By working together fluid structures can represent many continuous variables in relational context. This can be especially useful in representing interrelated high dimensional spaces and transforming them into more useful configurations. Equivariant transformations typify this Archetype. That is a transformation so that if the input is transformed in a certain way, the output undergoes a related transformation.
Equivariance niche - Value in equivariant transformations that keep relational data intact.
Note that this ability for many neuronal inouts to transform high-dimensional relational data is synergistic with the compression and decompression niche. Often the relational data needs compression or expansion. These niches often overlap.
Another valuable use of fluid structures is akin to the kernel trick. This is where the fluid structures represent high dimensional data and then transform it in such a way so that it becomes easier to linearly separate. This can allow for easier detection further within the network.
Kernel niche - Value in transforming data in order for that data to be more easily linearly separated.
Fluid transformations can also be valuable for directly mapping representations to responses. Given this input situation (mapped via multiple continuous variables) create this output response (mapped via multiple continuous variables). This may not be the most optimal mapping but is often the easiest and first to form because backpropagation works along a gradient. As we will see, other archetypal structures can also fill this niche.
We have seen a niche for connecting input to output space before. We are essentially describing the top-down prescription niche we found in chapter 5. However, in this case we are specifically describing a continuous mapping between the input and output space.
Continuous Prescription niche – Value in a continuous mapping from input representations to output responses.
Putting all this together, perhaps the most impressive trick of the Archetypal Fluid Structure is that it alone can create effective global input-to-output mappings. That is to say, for some domains and at certain points in training, all inouts may exhibit the qualities of archetypical fluid structures. Fluid transformations can do this because the continuous compression niche, the continuous decompression niche, the equivariance niche linked with the prescription niche essentially performs all the core functions of a learning network. The equivariant transforms can represent the relational structures within the input and output space. The continuous compression niche can select useful variables to isolate, and the continuous decompression niche can expand behavioral commands to actuator actions. Finally, the continuous prescription niche can bridge the gap between the lot. We will dig into this in detail in later chapters.
When many fluid-structure-inouts work together they create an extremely generally applicable structure. It is applicable in so many situations that it is almost easier to define it by the rare situations where it is not the most valuable solution. We will, over the course of subsequent discussions, get a good instinct for this. But generally, it can be explained thusly: The fluid structure does not allow for good discrete decisions and thus predictable certainty.
This becomes problematic in many situations. Consider for instance, output behavior. In many domains producing one output behavior excludes producing another and there is no middle ground solution. This puts high value on defining distinct behaviors that the network can produce… and that requirement for a distinct choice extends to the recognitions which helps the network decide. The Archetypal Fluid Structure is not good at making such certain and discrete declarations.
The standard archetypical structure
In our symbolic growth hypothesis, we will hypothesize that you should generally consider all neurons to start as fluid structures. Given training and backpropagated direction the fluid structure can change into other structures. If this structure starts utilizing its nonlinearity, it turns into a detection structure. If this structure starts forming situationally disconnected inputs, it can split into two inouts or move towards becoming a trigger structure.
Given certain conditions, Fluids will slowly morph towards the detection and trigger polar directions. Indeed, it is questionable whether they ever become true triggers and detectors, and instead just move in that structural direction. Our archetypal structures are after all based on extreme poles.
Also important to consider. Our symbolic growth hypothesis will suggest that even once a fluid structure morphs into a different structure, these new triggers and detectors will still be contextualized and enveloped within the fluid structure grouping.
Archetypal Detection Structure
An inout with the Archetypal Detection structure has inputs that are situationally connected and low in influence. This inout also has a neuronal output frequency that is lower than the average output frequency of its inputs. This means it utilizes its nonlinearity to become somewhat sparse. Only specific combinations allow for significant neural output.
This combination indicates a proficiency for detecting combinatorial patterns within the input. Its output prototypically fires in a somewhat discrete manner indicating whether or not it has detected the pattern. We say somewhat discrete because it is not actually discrete. The neural network backpropagation technique requires a continuous gradient, and so the output of a neuron is designed to never be discrete. Thus, when we say somewhat discrete, we indicate only that the neuronal output has moved further in that discrete direction than normal. We could for example, be dealing with a continuous variable that has an “off state”. The details of this relies on the exact activation function in use and its non-linearity.
The Archetypal Detection Structure exemplifies neurons that recognize unique combinations of input. Detecting a curve, a circle, a dog, a car… these types of pattern recognition all require recognizing unique combinations/patterns within the input data, and then building those patterns on top of each other. Such types of neurons are well known and have been empirically explored.
Pattern recognition niche - Value in recognizing and representing specific combinations of patterns from the global input. Provides a signal about a valuable selectively filtered element.
Below is a visualization of a circle detector within the inception network. All these neurons recognize a unique combination of input and likely exemplify the archetypal detection structure. Where the inputs are situationally connected, and all slightly influence the neural output so that only a specific input combination activates the neuron to a significant degree. The change in output frequency declines because significant input signals are more frequent than the final output which is only significant when an exact combination is present. Or more accurately, the combination is likely a range of input variation... and that range may or may not correspond to meaningful variation in the output beyond the nonlinearity.
An Overview of Early Vision in InceptionV1 (distill.pub) [8]
The pattern recognition niche is a big niche. This begs the question can we subdivide it into smaller partitions? Can we do this without relying on training set specific niche definitions? We believe the best way to do this is via an abstraction metric. Where pattern recognizing detectors high in abstraction have a rather different role than pattern recognizing detectors low in abstraction. We will explore this in a later chapter.
The other method of subdivision relies on our top-down specializations. You can describe pattern prescription detectors which perform pattern recognition on the signifier divide. So that its inputs recognize patterns from the global input, while its output represents a response in the global output.
Regulation niche - Value in recognizing specific combinations of patterns in output decisions. Provides a signal which valuably changes behavior based not on the global input, but instead based on internal behavioral output conditions.
We also hypothesize that you can find detection structures within the response niche, on the output side of the network. It is likely valuable in many situations for a detector to input various output response signals and recognize certain combinations. As a simplified example, imagine two behavioral responses: “turn right” and “turn left”. The two behaviors are contradictory. If two neurons represent those behaviors, one can imagine a valuable role of a detector structure taking these two neural outputs as input and detecting the conflict. The detector could then valuably suppress both of the behaviors until one is significantly more active than the other.
We could perhaps break up the regulation niche into multiple subniches.
Bad-combo niche - Value in recognizing specific combinations of patterns in output decisions as a bad combination and suppressing the conflicting behavior.
Also-do-this niche – Value in recognizing specific combinations of patterns in output decisions as also requiring another behavioral change. You could imagine situations where the detector recognizes the combination of a signal for behavior a and b and has learnt that this combination also can valuably utilize behavior c.
Archetypal Trigger Structure
The Archetypal Trigger structure has inputs that are situationally disconnected and strongly influence the output of the neuron. Thus, the inputs tend to occur separately but if any input fires, it “triggers” the neuron. This naturally increases the neuronal output frequency when compared to the average output frequency of the inputs.
We have defined four separate ways the Trigger structure is valuable.
Invariance niche - Value in creating invariant transformations. Filtering out specific types of information as unwanted noise. Provides a denoised signal.
Invariance is when a representation filters out a type of variable change. For example, imagine a neuron that fires when a dog head is present no matter the rotation of the dog head. Such a representation is invariant to rotation. The ‘dimension’ of rotation is treated as noise and disregarded in the recognition of “dog head”. Invariance is often very valuable. There are many dimensions that can be valuably disregarded in different contexts. Scale, rotation, translation, hue, brightness/contrast, occlusions, noise, deformations, etc.
The best time to deal with invariance is often as soon as possible. That’s because the invariance trait is carried onwards by latter recognitions. For example, if some curve detectors are invariant to hue, then the recognitions that utilize these curve detectors will also be invariant to hue. Thus, it’s a fair prediction that we are likely to find invariance circuits early within a neural network.
We can imagine invariance being solved via Archetypal Trigger Structures. Imagine a set of recognitions being made given different hues, then imagine feeding all of these into an archetypal trigger neuron i. Now no matter which recognition is made with whatever hue, neuron i will activate. Neuron i is now invariant to hue.
Below you can see an image from a paper by Chris Olah’s team, they isolated a pathway where recognizing a dog’s head becomes invariant to the direction the dog is facing. In this picture we predict that the “union” step is done by an archetypal trigger neuron. Either alternative… either orientation… will trigger that neuron.
Zoom In: An Introduction to Circuits (distill.pub)[7]
Grouping niche – Value in grouping various representations (in the global input) so that any individual representation produces a recognition of the group.
We also hypothesize that the archetypal trigger structure is valuable in grouping representations. This is where a set of representations can be considered within a group, and the firing of one representation within the group triggers the recognition of the group.
This is very similar to invariance. The difference we are highlighting is that within a grouping, the alternative representations that make up the group define the group. For example, the various foods within the fruit class help to define the grouping. While with invariance, the alternative representations define a dimension that “does not matter” and can be thrown out. For example, the various spatial areas a cup could appear in does not help define the cup.
Controller niche - Value in acting to produce a set response in the global output. Provides a valuable signal to behave in Y way.
We also hypothesize that the archetypal trigger structure is valuable in representing discrete behaviors that affect the global output. In such cases we hypothesize that it acts a bit like a controller for that behavior.
To see why, consider a simplistic neural network within an ant. Now, consider a valuable output behavior like “walk” or “run”. If a neuronal output triggers such a behavior, that trigger needs to be utilized in a wide range of situations. An archetypal trigger structure allows for many situationally disconnected inputs which can all independently “trigger” or “control” the valuable output behavior.
That example is likely simplistic, and we imagine in reality, multiple levels of trigger structures interacting with fluid relational data before any changes in the global output are made. The point stands, however. A valuable behavior is often valuable in multiple situations. Therefore, the neuron representing the valuable behavior often needs to be connected to various situationally disconnected inputs.
The controller niche can further be divided based on our top-down deductions. We can describe controller prescription triggers. The controller prescription niche lies on the signifier divide and is defined in that its input represents a set of variation within the global input whilst its output represents a set of variation in the global output.
Framing niche – provides a signal with value as an external clue to affect other recognitions within the global input.
Finally, we have the framing niche. We hypothesize that there are situations in which it is beneficial to “frame” the input recognition process in a certain light. For example, in a fight or flight moment, different things become important. Your pattern recognition is shifted in favor of recognizing certain things and then behaving in certain ways. You could then equally consider this niche the “attention” niche because it is often about shifting the attention of the recognition side of the network.
Generally, however we can describe this niche as providing some external clue to an inout of interest. Where “external” means that the clue is not directly or entirely derived from the patterns that make up the representation of the inout of interest. For example, recognizing a face can provide a signal to help you recognize partially excluded eye within the face. That signal is not entirely derived from the eye and so is “external” to the eye representation. This will be discussed in more detail later.
This utilizes the trigger structure, because like the controller, the framing effect can be valuable in multiple situations, and so multiple situationally disconnected inputs need to effect it.
Important caveat to the controller and framing niche
The controller and framing niche have an important and informative caveat connected to them. The trigger structure only fills these niches when an action is generally valuable in multiple situations and these situations have been connected under said trigger structure. The alternative is that a trigger structure never forms and so these niches are not fulfilled by a trigger structure but instead by the outgoing connection of the detector that isolated the single situation. That outgoing connection is still within the respective niche because the niche itself is more about the value of the signal. It is just the case, that in many situations these signals are useful in multiple situations, and so a trigger structure forms.
Contextualizing and summarizing
To help see the picture we are developing we are going to paint a rough sketch of where we are going and summarize where we have been. To do this properly requires a level of detail we don’t have yet. We need a better understanding of how these archetypal structures work together in larger groups, how they develop, and we need a properly grounded definition of abstraction. We shall delve into all these in future sections. For now, rough sketch.
First, we have divided neural networks from a top-down point of view. We have deduced that without loops, the network will develop a signifier divide which creates a recognition-to-response format. Given this we deduced some niche definitions.
Representational niche: Value in representing variation or features within the global input or output.
Recognition niche – Value in recognizing and representing parts of the global input.
Response niche – Value in representing and altering parts of the global output.
Prescription niche – Value in connecting recognitions on the input side to responses on the output side.
Helper niche: Value in generally helpful actions upon representations without those actions relating to the representations themselves.
We then delved into a bottom-up perspective. We studied neural structures. We found that neurons are not the best unit for considering representation because sometimes they can be divided situationally so that the output represents different things at different times. Where input group 1 during situations set 1 produces meaning 1, and input group 2 during situations set 2 produces meaning 2. While it would have been easier to define representative inouts based on situational groupings of inputs, we found that sometimes situationally separated input sets can connect to an output with the same meaning. This complicated the picture. Generally, however, we defined a representative inout as an input-to-output mapping with a distinct and differentiated output meaning.
We then found measurable differences between these sub-neural and neural inouts. These measurable differences we sinfully simplified (to which we confess to loudly). Given different combinations of polar extremes along these simplified but measurable dimensions, we defined a set of archetypical structures. Four of these we claim sub-neural and neural inouts can valuably form into: fluid structure 1, fluid structure 2, the detection structure, and the trigger structure.
We then began to define niches in which the form of these structures can valuably function. We shall roughly contextualize these within the larger structure of the neural network here via a series of diagrams. We call these diagrams RepLeStruct diagrams, and in the appendix, you can read about the various details involved with them. Generally, however, note that they are only a simplified approximation.
In reality we predict that you are likely to find every archetypal structure throughout neural networks, only their concentrations change with context. The niches we point to within the RepLeStruct diagrams describe a general proposed idea of what types of structures you would find where and why. In representing such a complex domain, we necessarily needed to simplify, and that simplification creates a degree of inaccuracy. For example, we often depict a trigger or detector structure above a fluid structure. This indicates that the trigger/detector is encapsulated within the fluids relational context. In truth, we hypothesize that every detector/trigger is somewhat encapsulated within such a context. However, at higher abstraction levels, the context becomes more global and so less relevant. Thus, at higher abstraction levels we drop the fluid symbol.
Archetypal fluid structure niches:
Continuous compression niche – Value incompressing continuous variables into a selected form.
Continuous decompression niche – Value indecompressing continuous variables into a selected form.
Kernel niche - Value in transforming data in order for that data to be more easily linearly separated.
Equivariance niche - Value in equivariant transformations that keep relational data intact.
Continuous Prescription niche – Value in a continuous mapping from input representations to output responses.
The fluid structure, as we noted, can singlehandedly perform an effective input to output response. As we will see in later chapters, we hypothesize that neural networks start this way and over training form detection and trigger structures.
Archetypal detection structure niches:
-
Pattern recognition niche - Value in recognizing specific input combinations of patterns. (from the global input)
a. Can be subdivided based on abstraction level.
b. Pattern prescription niche – Value in recognizing specific input combinations of patterns to directly produce a set response in the global output.
-
Regulation niche - Value in recognizing specific combinations of patterns in output decisions. Provides a signal which valuably changes behavior based not on the global input, but instead based on internal behavioral output conditions.
a. Bad-combo niche - Value in recognizing specific combinations of patterns in output decisions as a bad combination and suppressing the conflicting behavior.
b. Also-do-this niche – Value in recognizing specific combinations of patterns in output decisions as also requiring another behavioral change.

We will hypothesize that the detection structure grows out of the fluid structure and is often contextualized by it especially at lower levels of abstraction.
Notice also in the above structure that we will hypothesize multiple valuable pathways at different levels of abstraction. This image is not meant to cap this at two pathways, it could be (and likely is) more.
Archetypal trigger structure niches:
Invariance niche - Value in creating invariant transformations. Filtering out specific types of information.
Grouping niche – Value in grouping various representations (in the global input) so that any individual representation produces a recognition of the group.
-
Controller niche - Value in acting to produce a set response in the global output. Provides a valuable signal to behave in Y way.
a. Controller prescription niche - Value in acting given direct global input recognitions to produce a set response in the global output.
Framing niche - provides a signal with value as an external clue to affect other recognitions within the global input.

The invariance niche is placed early in the network, this is a prototypical simplification. There are certain types of invariancies which happen further in, for example, invariancy to dog head orientation relies on a decent number of pattern recognitions to be made beforehand. You may notice that the invariancy niche does not increase abstraction, we will discuss this wrinkle in a later chapter.
The grouping niche groups various representations so that any individual representation produces a recognition of the group. This also can happen at multiple points throughout the recognition portion of the network.
The controller niche represents some output behavior and is then connected to multiple situational inputs that may activate said behavior. It is then placed within the response portion of the network wherever the input side and the output side meet. The controller niche, if identifiable, is likely a good indicator that you have crossed the signifier divide.
Finally, we have the framing niche. The framing niche is a valuable action that broadly affects pattern recognition throughout the recognition side of the network. This valuable action is then grouped under different situational input signals. Often this valuable action is, pay attention to x! The framing niche is a bit of a problem-child especially when we come to abstraction, but we will discuss that later.
We do not claim at all to have an exhaustive list of specializations. Trying to create such a list would misunderstand what niches are and how they are defined. For now, we will begin with the above categories. But let’s be clear, there are many more and they will come with a form that best fits function given conditions. Here are some possible others, however these are ungrounded in any structurally identifiable considerations (yet).
Noise reduction niche – value in reducing noise or unrelated signals within a channel of information.
Robustness niche - value in multiple pathways when one may be compromised.
Pass along niche – value in passing along information without any transformation or recognition. This is sometimes valuable as to work around architectural constraints.
Speed niche – value in speeding up output response time through parallelization. (Found in the brain and GRN, currently less valuable in artificial neural networks.)
Temporal niche – value around forming sequences and loops.
Goal representation niche – value around forming an internal goal and measuring your progress towards that goal.
And many more…
Niches define a direction of value. One can define infinite directions. The trick is to define niches so that we can identify inouts that provide that value. The trick is to ground our definition of niches within a predictive model.
Our current set of niches already allows us to make some predictions. We can say, for example, that we predict there to be more detector style archetypal structures on the input side of the signifier divide than the output side. We can say this based on the hypothesis that the pattern recognition niche is much larger than the regulatory niche.
Notice that this is a measurable prediction! We can go into a neural network structure and define a threshold on our measurable dimensions via which we can define detector archetypal structures. Notice also however that this requires us to know where the signifier divide is! That is perhaps a harder task. We need to understand multi-neural symbolic structures and abstraction to a greater degree if we wish to do that. How do these structures work together? How do they form? How is abstraction involved? What does a mature input-to-output response look like?
We are on that path, but there is further to go. In the next chapter we start looking at multi-neural symbolic structures.
7. Multi-neural Symbolic Structures
Symbolic structures.
In this chapter we zoom out. Instead of considering sub-neural and neural inouts, we consider large groupings. In this endeavor we define symbolic structures as groupings of inouts forming computational mechanisms specialized for recognizing patterns within the global input or generating patterns in the global output.
We can consider symbolic structures on the input and output side of the signifier divide. On the input side these structures are made up of inouts from the recognition niche. On the output side these structures are made up of inouts from the response niche. Whether or not there is a continuous division along the signifier divide is still in question.
Input-side symbolic structure: This refers to a computational configuration that is tuned to recognize variation in the global input through specific patterns or features. The variation should be correlated to some external entity, or situation.
Output-side symbolic structure: This refers to a computational configuration that is tuned to produce a specific range of variation in the global output, corresponding to particular behaviors or responses.
It is important to note that our definitions of symbolic structures allows for structures that do not reach the signifier divide. Indeed, a first layer input-side neuron in a network could be defined as a “computational configuration that is tuned to recognize variation in the global input through specific patterns or features.” And the last neuron in a network could be defined as a “computational configuration that is tuned to produce a specific range of variation in the global output”.
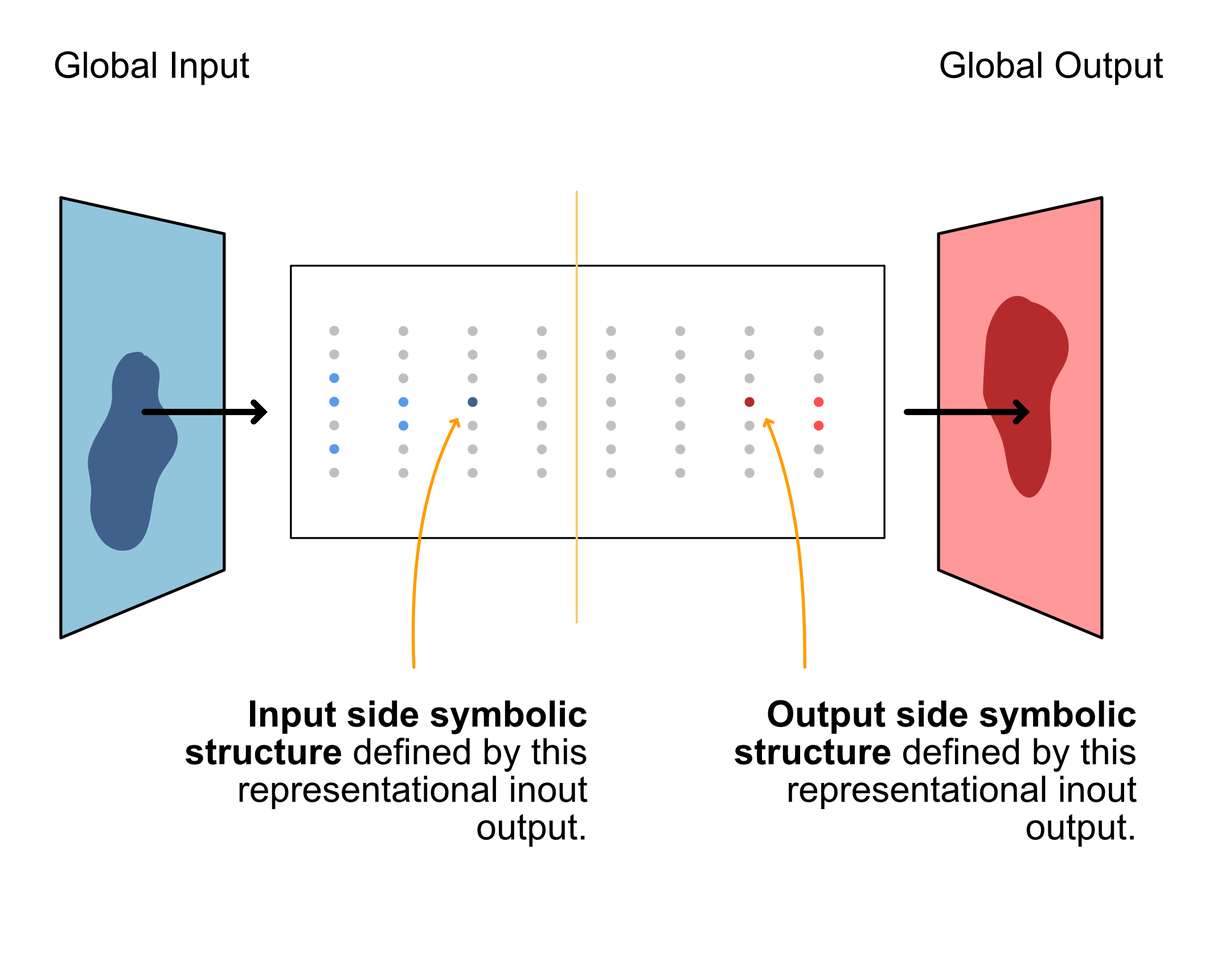
Symbolic structures can be made up of different archetypical structures. A symbolic structure made up of fluid structures is going to be different from one made up of detectors. In reality we expect mature symbolic structures to generally be comprised of all of the archetypical structures. However, in order for us to explore the complexity we begin with simplicity. We will begin by considering structures made up entirely of each archetypical structure. We will then consider how this affects the symbolic representations they create.
Fluid symbolic structures.
First let’s consider symbolic structures entirely made out of the archetypal fluid structure. Single Fluid structures take in multiple continuous inputs and produce a continuous output. However together in a grouping, fluid structures can expand, and contract information channels and they can represent relational space.
Generally, the output of a single neural inout with an archetypal fluid structure tells you little. But in a grouping, with context, these can be symbolically powerful. The output of the grouping can define a multidimensional vector space that represents interrelated data from the global input or represents an interrelated response in the global output.
Perhaps the easiest intuitive example of this is in considering the input-to-output mapping of catching a ball. Whilst there are high-level discrete abstractions involved, the tough work is likely being done by archetypal fluid structures. Consider the multi-dimensional mapping of where the ball is in the input space and connecting that to the multi-dimensional mapping of where your hand needs to be in the output space. This is exactly the type of equivariant transformation that we hypothesize archetypal fluid structures excel at.
Individual fluid structures often have little individual meaning, instead the representational meaning requires the relational context of group of neuronal output. This means that to best represent a symbolic structure made of fluid archetypes, we generally consider a grouping of interest.
Within the recognition niche, a fluid symbolic structure is defined by a grouping of neuronal output on the input side. The structure then incorporates all the upstream neurons/inouts that lead to this grouping of neuronal output. Thus, we imagine an inout that maps from the global input to the resulting output of the grouping of interest i. In other words, the grouping of interest is the output of the multineural inout, and the multineural inout’s input is the upstream global input that affects the grouping (the external local input).
On the response side, it is switched. The fluid symbolic structure is defined by a grouping of neuronal input on the output side. The structure incorporates all of the downstream neurons/inouts that lead from this inout of interest to the global output. Thus, we imagine an inout that maps from the local input of the grouping j to the resulting effect on the global output.
These definitions are useful because they are grounded in what these symbolic structures represent. On the input-side, the structure describes the compression process from input to symbolic representation. On the output-side, the structure describes the compressed representation and the causal expansion towards behavior. The symbolic structures are grounded in what they represent within the global input or the global output.
How to define meaningful fluid groupings?
Defining the groupings of interest is difficult. What groupings together make up coherent representations? We cannot assume these neural connections are laid out in clean parallelizable pathways that we can isolate.
In considering this, we find a problem with some reminiscent qualities. We are trying to isolate groups based on what they represent. This is a very similar problem to the problem of distinguishing sub neural inouts. Like distinguishing sub-neural inouts, utilizing situational frequency is likely an important piece of the puzzle. For example, meaningful groupings of interrelated representations are likely to have similar situational frequencies. However, now the problem is on a larger scale and at an even higher dimensionality. We will not dig into addressing this problem, it is well out of scope.
For our current discussion, let us explicitly notice that the fluid symbolic structure is divisible. Groupings can be defined in layers in between the grouping of interest and the global input/output. If the fluid symbolic structure is performing some type of transformation, this in-between point can be considered a part way point of a greater transformation.
Discrete symbolic structures
Let’s now consider symbolic structures that are more discrete in nature. Where a neuronal output has a discrete meaning and does not rely on some interrelated grouping.
In this effort we are going to imagine a simplified pathway comprised of detection and trigger structures. We call this an idealized discrete pathway. With the input side symbolic structures being made out of archetypal detection structures, and the output side symbolic structures being made out of archetypal trigger structures. So, you should imagine the input side detects patterns on top of patterns until some abstract recognition is activated. Then this recognition is connected to a “trigger” response. This trigger response then triggers a cascade of further output responses.
It is important to note that we believe that such pathways are unlikely in reality. As we will see in our symbolic growth hypothesis, we suggest that discrete structures like detectors and triggers are contextualized and grow out of an interrelated fluid transformation. Given this, a pathway fully comprised of detection and trigger structures, we consider very unlikely… within neural networks. Perhaps in other learning networks, like the gene regulatory network, this may be more common. In gene regulatory networks, discreteness may be the standard starting state of inouts, unlike neural networks. (truth is more complicated see appendix)
On the input side, a discrete symbolic structure is defined by a recognition-niche neuronal output. The structure then incorporates all of the upstream neurons/inouts that leads to this neuronal output. Thus, we imagine an inout that maps from the global input to the resulting output of neural inout i.
On the output side, a discrete symbolic structure is defined by a response-niche neuronal output. The structure incorporates all of the downstream neurons/inouts that lead from this inout of interest to the global output. Thus, we imagine an inout that maps from the local output of inout j, to the resulting effect on the global output.
These definitions describe each symbolic structure as a mathematical tree from the neuron of interest towards either the global input or the global output. We define symbolic structures as such because we have previously deduced that they get their value from describing or controlling change in the global input and output. This reference frame captures what is important given the inout’s respective niche. On the input side we capture the set of processes that leads to the recognition of the situational feature. On the output side we capture the set of processes that allows the inout to change the global output.
Symbolic structures along an idealized discrete pathway have a valuable property. We can define a single neuronal or sub-neuronal inout of interest on one side and the global input/output on the other. Then we can assume that the individual inout represents some discrete set of variation within the global input or output. We do not need to go to the trouble of defining continuous groups of interrelated contextual representation as we did with the fluid structure.
It is important to note that these symbolic structures can utilize common inouts. Input side symbolic structures rely on earlier symbolic structures to make their recognitions of variation first. Output symbolic structures incorporate later symbolic structures by changing their output behavior.
In this way we can say symbolic structures can be nested. A symbolic structure can have within it further symbolic structures. For example, a symbolic structure may be tuned to recognize “lines”, whilst another symbolic structure can utilize that “line” recognition to recognize a “face”. One must imagine a large interlacing set of these symbolic structures that activate depending on the input.
Because these symbolic structures are essentially mathematical trees, we can use mathematical tree metrics to describe them. We can discuss the number of leaf nodes, the number of branches, the number of internal nodes, etc. These metrics, however, do need to be recontextualized within this general learning network model. For example, unlike a classical mathematical tree, the leaf nodes here are under a constraint. A leaf node is defined by being connected to the global input (or global output if we are considering an output side symbolic structure).
Finding the symbolic tree structure.
Finding these symbolic trees is well outside of our scope, but “a problem described is a problem half solved” and so we will have a quick discussion on the issue.
First off, many others have worked on similar problems. There are various forms of algorithms which find causal influence through a neural network. Propagating relevance scores, occlusion methods, gradient-based attribution, etc. [14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26]. Such methods can, with some work, be applied to find symbolic trees. It is important to recognize however that such methods can only ever provide an approximation of the structures we are discussing.
Symbolic structures are exceedingly complex because various ranges of inputs trigger multi-dimensional causal sequences. That is to say, the input phase space that activates a symbols neuronal output is large. We would have to sample through all input ranges to get a true picture. Approximations are likely the best we can ask for.
The other problem, of course, are the fluid structures. To elucidate, let us consider isolating a detector neural inout and finding its symbolic structure. Given we are considering true measurement, we have to contend with the fact that this detector is likely contextualized within one or more fluid groupings.
Imagine for instance a detector that detects a circle within a visual model. Without some enforced structure like convolutions, the relational, spatial information is likely codified and embedded by fluid structures. If we were to imagine ascribing causal affect through such a fluid grouping, we have a fundamental problem. The fluid grouping’s meaning comes from interconnecting and contextualizing the space.
We have two options. First, we could include the entire fluid grouping that relates to spatial information. However fluid groupings create relational context by connecting everything along a dimension. By including the fluid groupings, the symbolic structure would likely connect to every part of the global input and thus be rather unhelpful. Or second, we could attempt to divide up the fluid structure and only select the portions of the fluid structure which relate to the spatial location of the circle. This is likely the best solution, however it has its own trappings. Afterall the spatial location of the circle only makes sense within the context of the larger fluid grouping.
If we were to truly describe symbolic structures in detail, we would need to ascribe more dimensions to our interpretability model. The likely best “futuristic” solution would be to understand each fluid structure and what relational data they convey. Then when we attribute a part of a symbolic structure through the fluid, we understand exactly what context is being added, and how the attribution should be handled. This futuristic solution would require us to isolate and understand fluid structure groupings… which has all the problems and trappings that we described previously.
This is all to say, that once we start ascribing causal influence through a fluid grouping it becomes very difficult to detangle which inout influences which, to what degree, and in what way.
Signifier divide hypothesis: Is the signifier divide continuous or discrete?
Let’s imagine a pathway of archetypal fluid neurons connecting global input to global output. Close to the global input, the multi-dimensional vector represents some input data with important relational connections intact. For example, the size, speed, and location of an incoming ball. Close to the global output, the multi-dimensional vector represents some output data with important relational connections intact. For example, where the hand should be, the configuration of the fingers, the expected impact time and effect, etc. The question is… what does the multi-dimensional vector in the middle of the fluid transformation represent? Is there a point where the fluid transformation suddenly stops representing the global input and starts representing the global output?
Now let’s imagine a pathway of archetypal detection and trigger structures connecting global input to global output. Close to the global input, there are a series of pattern detections. For example, lines, curves, colors, etc. Close to the global output there are a set of triggers affecting changes in the global output. For example, triggers to move this and that nerve to trigger hand movement. The question is what do the discrete detections and triggers in the middle of the pathway represent? Is there a point where detection of the global input suddenly stops and now represents change in the global output?
We hypothesize:
The pathways made up of more continuous archetypal fluid neuronal inouts, will have a more continuous signifier divide.
The pathways made up of more archetypal detection and trigger neural inouts will have a more discrete signifier divide.
The intuition for the continuous fluid transformation is that every point in between global input and global output is an “in-between” stage of the transformation. No point offers any clue that you have gone beyond the point of representing the input and have now begun representing the output. There is no reason to believe that there is a discrete divide.
The intuition for the discrete transformation is that there is a point in between the global input and global output that signals a discrete change. When the pathway switches from consisting of archetypal detection structures to archetypal trigger structures a phase change has happened. For example, when an abstract detection of the ball connects to an abstract “try-to-catch” trigger. Such a discrete switch in representation happens all the time in computer programs. Where a discrete “if x” recognition triggers a discrete “do y” response.
There is actually an information theory intuition to this. Each detection structure recognizes patterns in the input. As these symbolic structures build on top of each other, pattern recognition builds on pattern recognition. Each step in this process means that the deeper neural level inouts have more useful information about the outside situation than the neural inout before it. However, at some point this stops begin true. Once you pass the signifier divide, deeper inouts begin to know less about the current situation.
This is because you have switched representational domains. Each step past the divide is increasing the complexity of describing a representational niche inout in terms of the input. To understand why this is the case consider that trigger inouts within the response niche represent some change in the global output. However, a neural output representing some behavioral change in the global output is generally useful in multiple situations. The response is to some degree invariant to the particular situation that causes it to trigger. This is behavioral modularization. Each step deeper into the output side increases the combinatorial possible input situations.
We could also describe this in terms of the output frequency of discrete inouts. Pattern detectors by their nature filter out possible situations, and so each subsequent detection becomes less represented within the dataset. That is, the output frequency decreases as you stack detections on detections.
On the output side, the opposite occurs. The most downstream triggers can be utilized in more possible situations, and so each subsequent trigger becomes more represented within the dataset. That is the output frequency increases as you stack triggers on triggers.
This shows once again a representational domain shift. While this happens within fluid structures too, with the idealized discrete pathway we can see a discrete and sharp divide. That is where the detectors turn into triggers. Of course, when we relax these idealized pathways constraints, reality becomes more muddled. There are important niches of value for triggers within the input side that increase the output frequency.
Given future arguments in the symbolic growth hypothesis this idealized discrete pathway looks unlikely. There, we conclude in a neural network trained by backpropagation, detectors and triggers are always* contextualized by fluid structures. Therefore, in a neural network, we do not believe the signifier divide is really ever “sharp and discrete” though it may be much “sharper and more discrete” in some places than others.
8. Abstraction
“Compression IS intelligence” … this is a reductive phrase circling around. It does, however, capture the importance of compression. It may be closer to say: “Selective compression builds valuable representations, and it is the interactions between these representations which provides valuable input-to-output mappings… Better input-to-output mappings IS intelligence.”
There is a well-studied phenomenon that neurons that are deeper within neural networks often correlate with higher-order representations of external phenomena. For example, at the beginning layers you might get neurons representing lines and curves, while at later layers you might find neurons representing faces, dogs, cats, etc.
This is often termed abstraction. Where pattern recognition builds on pattern recognition, all the while filtering out irrelevant information. There is power in building representations on top of representations. Each representation you produce provides the capability of recognizing a higher-order pattern. A higher-order pattern that may be generally applicable in a series of situations. Abstraction is the selective compression of situational input into valuable variables that can be acted upon.
This phenomenon is well documented and widely considered. In this deduction we explore abstraction by defining a metric for abstraction. We want to be able to say that inout A’s output is more abstract than that inout B’s output. That inout A recognizes a more general abstract pattern.
In information theory, abstraction can be defined thusly:
Given a channel of information X, with a probability distribution P(X)
Entropy H(X) = -Σ P(x) log P(x)
The process of abstraction transforms X into a new channel Y so that H(Y) < H(X)
We can compare two different information sources X1 and X2 that are abstracted to Y1 and Y2 by comparing their relative entropy reductions.
This can similarly be achieved by comparing the bandwidth between X and Y.
Given a channel of information X, with a probability distribution P(X)
Bandwidth = B(X)
The process of abstraction transforms X into a new channel Y so that B(Y) < B(X)
We can compare two different information sources X1 and X2 that are abstracted to Y1 and Y2 by comparing their relative bandwidth reductions.
Applying this framework to our general learning network model allows us to leverage a shared reference (the global input) to proportionately compare their abstraction levels.
Let B(X_G) represent the total bandwidth of the global input.
Let X1 represent the portion of the global input relevant to the abstraction Y1.
Let X2 represent the portion of the global input relevant to the abstraction Y2.
We can consider the Compression Ratio as a metric for abstraction. Abstraction = Size of Uncompressed Data : Size of Compressed Data
A1 = B(X1) : B(Y1)
A2 = B(X2) : B(Y2)
Now our abstraction metrics represent the proportional reduction in relevant bandwidth. With such a metric we can compare the abstraction levels of inouts.
This formulization suggests that if we select one discrete representational inout of interest, we can proxy measure abstraction by counting the leaf nodes during activation. These leaf nodes after all represent the portion of the global input which is utilized by the representational inout of interest. We can assume that they represent the portion of global input relevant to the inout. Thus, we are finding the external local input size of our symbolic structures.
Ai = B(external local input for i) : B(inout I’s output)
This is nice and clean when considering idealized discrete symbolic pathways. Those entirely consisting of detectors building up patterns until a decision is made triggering a cascade of output response through a series of trigger structures. But in reality, as we described in the last chapter, measuring and modeling this symbolic tree is not to be considered simple. We could assume however, given current work is already well on track, that future software given a threshold of influence, will be able to track which neurons are affecting other neurons. So that given some neuron of interest i and some global input x, we can track which part of x caused i to fire, and which part of y (the global output) was influenced by i.
But even after assuming capable modeling software, using this external local input metric is easier said than done. In this chapter we are going to discuss these measurement problems. Generally the problems all come down to… we need to know what niche a neuron is in and what it represents in order to measure abstraction properly because the concept of abstraction is tied up in the particularities of the representation we are considering.
Please note that, as before, the actual measurement of abstraction is not required to continue with our theoretical deductions. We stick to conversations of measurement because in so doing the discussion tends to be more grounded. Regardless, ideas we explore during this conversation will become very useful in future conversations.
Generality and Abstraction
Before we jump in, I want to draw your attention to an important distinction. That is the difference between abstraction and generality. These can often be conflated. So here let’s define a grounded definition of generality so that, as we continue, we can discuss generality’s interesting relationship with abstraction.
Like abstraction we can define a relational metric of generality relevant to an inout of interest. It is simply the situational set of global inputs which cause the inout of interest’s output to “activate.”
s = { x ∈ X ∣ fi(x) > θ }
Here, fi(x) represents the activation function for neuron i, and θ is the activation threshold for that neuron. The set S thus contains all inputs x from the training set X for which the activation function fi(x) exceeds the threshold θ, resulting in the activation of neuron i.
This definition allows us to say inout a’s situational set s is larger than inout b’s situational set s and is thus active in more input situations. sa > sb therefor a is more general to the training set. This definition allows us to consider the differences in generality between two inouts in grounded terms.
We could further push this metric so that the input space is not defined by the training set, but instead by the phase space. This would stop our definition of generality being tied to the training set and allow our definition of generality to… generalize. In this case the situational sets would involve all possible inputs, including those outside of the training set. However, doing this would make measuring such a metric impossible and so we will stick to the original definition.
We will discuss generality further, but for now let us return to abstraction.
Archetypal structures – relating to abstraction.
In general, an independent neuron always increases abstraction. This is because it has more inputs than it has outputs, and so it almost always reduces the bandwidth of information, thus increasing abstraction.
Indeed, if abstraction is simply the compression of information, and we can measure it by counting the external local input, our base expectation is that the deeper into a network you go, the greater the abstraction, irrespective of what a neuron represents.
So, does abstraction simply always increase? Is it a valuable measurement that helps us understand what a neuron may represent?
To answer these and other questions, let us explore how our extreme archetypal structures relate to abstraction. Keep in mind, as always, that these structures may not be what we find in a neural network. They are archetypes based on the extremes of what we can measure. They simplify our exploration.
Detector Archetype
First let’s consider archetypal detector structures. These activate only when a specific combination of inputs are active. This takes a lot of complex input information and filters it into a semi-discrete detector of some state. How discrete and how much information depends on the activation function and how the non-linearity is being utilized.
Detectors are the quintessential structure of abstraction. Their structure is perfect for refining a set of data down to the detection or representation of some feature within that data. They build pattern on pattern, and it is the work of these units that we are most interested in when considering abstraction.
Each detector neuron in a chain can be said to increase abstraction to a significant degree. Each selectively filters out and selects for its specific combination of inputs.
This also has an effect on the relative generality of each neuronal inout in the chain. The selective combination and the decrease in output frequency corresponds to a smaller situational set. Thus, as detectors increase abstraction, they decrease generality. If only detectors structures are used, each “higher abstraction” becomes more specific and situational. If only detectors structures are used, generality always decreases. In such a model, the highest abstractions are very specific to a situation and are not well represented in the dataset.
Important to note that detection at different levels of abstraction can be valuable. It would be a mistake to think higher abstraction is always better. Instead, most mature input-to-output mappings involve multiple pathways at multiple levels of abstraction.
Fluid Archetype
The fluid archetype is continuous and offers no change in output frequency. This major difference means that generality is kept constant. The set of situations that causes the fluid structures inputs to be “active” also cause the output to be “active”.
The other major difference with fluid archetype is that the level of representation moves from the neuron to groupings of neurons. With fluid structures, no one neuron really represents a valuable channel of information, the information always requires the context of the other fluid structures around it. Thus, any final information reduction point is best described by a group of neural inouts.
Archetypal Fluid Structures tend to capture a large web of interrelated multidimensional data and transform that web into a different form. At this macro level, the filtering out of data is not fundamental.
It still does occur. When the number of input channels is reduced to a smaller number of output channels, information is selected and filtered. However, this structure also allows for the opposite: the addition of data by including more output channels than input channels. The fluid structure is thus capable of increasing, decreasing, and keeping abstraction constant.
Trigger Archetype
Finally, we have the archetypal trigger structures. These activate when one of the inputs are active. Each input acts like a trigger and can activate the output to a significant degree.
Trigger structures relationship with abstraction is complicated. The different niches of trigger structures push on the definition of abstraction. So much so that we expect disagreement on our conclusions based on the definition of abstraction. We welcome such disagreement and eagerly await intelligent counter points. Regardless the trigger archetypes and its niches push us to better refine our conceptualization of abstraction, and this is a useful exercise.
At first glance trigger structures seem to obviously increase abstraction. Like all neurons, they have a set of input channels, and they compress that information into a single output channel. The bandwidth has certainly decreased. Therefor abstraction increases. Good! Let’s start with this conclusion and discuss generality.
The trigger structure has an interesting relationship with the change in output frequency. The output frequency of the trigger rises when compared to its inputs average, because any individual input can activate it. The set of alternative inputs now all become grouped under the same representative output. Each alternative input increases the set of possible situations that allows the output to be active. This means that relative generality always increases with trigger structures.
You can thus imagine that linking detectors and triggers allows more abstract representations to be more general and to not continually narrow in and become more specific to a smaller and smaller set of situations. Detectors allow for selective interest; triggers allow that selective interest to generalize to a larger situational set.
Ok so generality increases with trigger structures, this seems quite simple no problems yet. The trouble comes however, when we start considering the type of information that triggers filter out.
When the trigger structure produces output, it filters out which individual input caused the output to fire. That is to say, that the output channel has lost any information regarding the specific instance that caused it to fire. This generally corresponds to an increase in abstraction… but arguably not always.
In information theory, if you are considering reducing the bandwidth of an information channel, we tend to not include the reduction of noise as a part of the reduction of bandwidth. Noise is typically considered an independent aspect. One could then argue that if a neuron is filtering out noise, then the neuron is NOT increasing in abstraction.
So how does one define noise here? Well… based on valuable communication. The majority of inouts valuable role is to represent. Represent something in the global input or the global output.
In building a representation you often filter out what a thing is not. But this is not noise. Defining something by what it isn’t… is helpful in defining what a thing is. For example, defining the meaning of a green light within a traffic light context requires defining the negative alternatives (the orange, and red lights). In symbol theory, this is called negative definition. This is not noise; this is a part of the game.
Instead, noise is defined by indifference. When a representation is made regardless of hue, size, or location, then hue, size, and location is considered noise to the making of the representation. These dimensions do not matter to the representation. If these dimensions interfere with the making of the representation, then that is negative noise.
We are describing the niche of invariance. To filter out dimensions which do not matter to the representation.
It is the archetypal trigger structure that allows for invariance. Imagine if a pattern at size a, b, and c can all independently activate trigger structure i. The output of trigger structure i then has conveys the pattern has been detected but has lost the information about whether it was a size a, b, or c pattern.
We suggest that we can think of invariance as essentially a denoiser along a specific dimension. Then because we classify the lost dimensions as noise, when a trigger acts within the invariance niche, it does not increase the abstraction level in relation to the symbolic structure it is a part of.
This is perhaps an annoying conclusion. It may mean that to measure abstraction properly we need to distinguish triggers that are within invariance niche. But our trials have just begun. Let us then consider the other trigger niches.
First the case where the trigger structure represents a grouping of other representations. For example, imagine it defines the class: mammals, and any mammalian animal representation triggers the higher-class representation. Well now the valuable representation, the class, is defined by the grouping of lower-representations (or features within that grouping). The grouping defines a border that is integral to the definition of the group representation. It does not define some “does-not-matter” dimension that is not relevant to the final output’s representation. In this case we would say that the trigger structure is not filtering out noise and is indeed increasing abstraction.
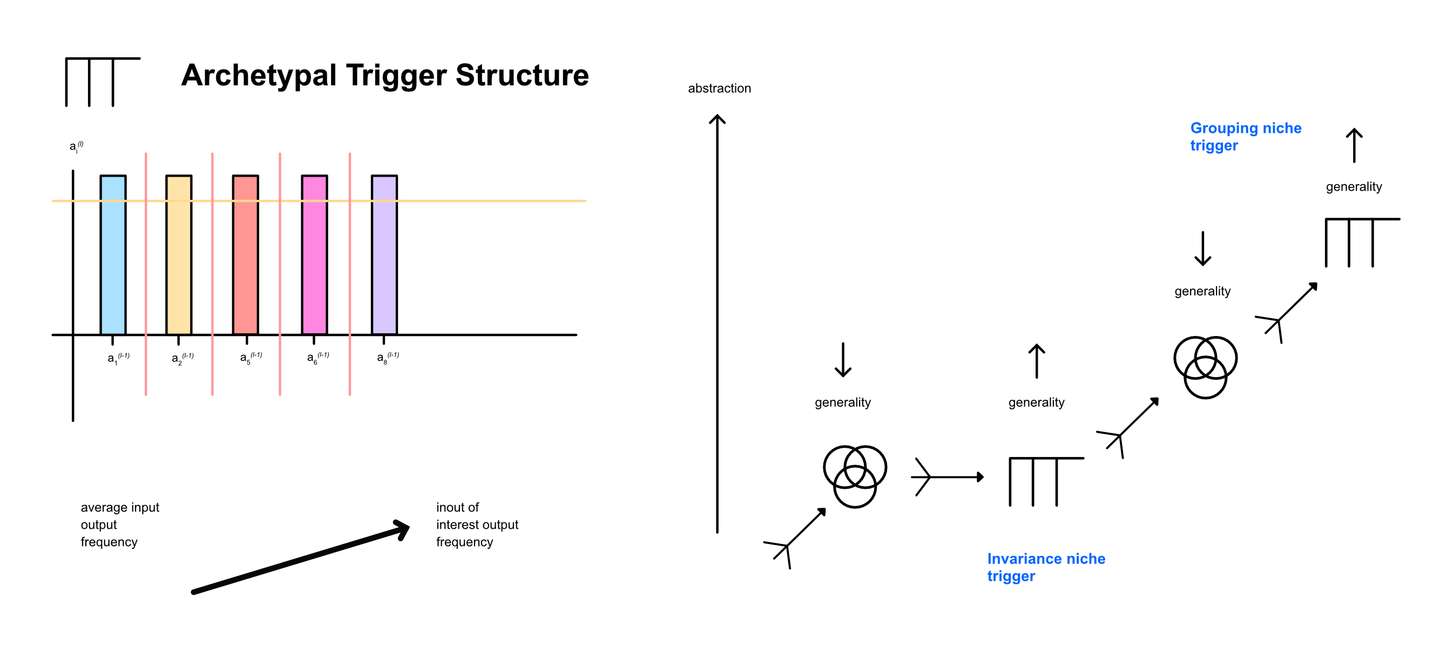
But then let’s look at the controller niche triggers. Let’s specifically consider the controller prescription niche. This niche has value in connecting input side representations to a response in the global output. Its inputs have representational meaning related to the global input, and its output has representational meaning related to the global output. How does this prescription niche interact with abstraction? Does crossing the signifier divide alter how we treat such inouts?
Note: this situation can also be considered with pattern recognition detectors on the input side linking to a single responsive signal on the output side.
We claim that crossing the signifier divide is a representational phase change. We have moved from one domain to another. In information theory terms, the information channel is now conveying a different message about different underlying phenomena. This is not compression or expansion this is a causational linking between two different messages. If x do y.
This is an interesting conclusion because it now suggests that there are multiple abstraction metrics depending on what the signal within the network is representing. Crossing the signifier divide moves us into a different representational domain and thus requires a different abstraction metric. In the following section we will flesh this out further by describing output abstraction separately and specifically. In that section, we will discuss controller triggers which do not cross the signifier divide.
This concept of multiple abstraction metrics based on the underlying message / representation offers a potentially fun / scary thought. Are there other times in which we move into a different representational domain? Well, the final niche within the trigger family offers perhaps the greatest curveball yet. We will however delay addressing the framing niche for the moment.
Output-side abstraction
Common wisdom within the academic community would have one measure of abstraction that rises as information gets compressed and falls as information gets decompressed. We argue that this is wrong because the information that is compressed represents something different than the information that gets decompressed. There is a change in representational regime.
Our general learning network model via deduction 4 & 5, suggest that a network, without looping structures, will form two representational sides: recognition and response. We therefore think it is fitting to split abstraction into two metrics for each of these sides.
Differentiating between input-side and output-side abstraction is a unique approach. However, we believe it valuable. Input-side abstraction relates to recognitions derived from the global input. Output-side abstraction relates to responses that affect the global output. They are two separate representational messages separated by the signifier divide. As we have noted earlier, this signifier divide is not exactly discrete. We hypothesized that fluidal structures form a continuous divide, whilst detectors and triggers form a more discrete divide.
So then what does output abstraction mean? Well, it is not commonly considered and so is perhaps less intuitive. While input side abstraction is generally based on the selective compression of information, the output side is generally based on the selective decompression of information. It is not defined by the global input being filtered into patterns which selectively filter upwards towards higher-order patterns. Instead, it is built on higher-order controls affecting lower-order controls which affect the global output. Just as input side patterns represent some set of variation in the global input, output side controls represent some set of variation in the global output.
Perhaps the best intuition for this is gathered by considering commands propagating through a hierarchy of humans. Consider a CEO making a command. Such a command generally refers to some high-order strategy and does not go into details. However, as the command travels down the hierarchy, the strategy is combined with “on-the-ground knowledge” and converted into more tactical commands. These commands for change continually become more specific and relevant to “on-the-ground context”. That is until the command reaches the many people who actually implement the tactics and produce change.
This is an addition of information, instead of a filtering. “On-the-ground” information is continually added to the higher orders. As you travel from the signifier divide to the global output, output abstraction generally decreases because this “on-the-ground” information is being added and expanded.
This is perhaps confusing because our model matches the common wisdom of the academic community in this area. We say there are two types of abstraction relating to representations from the input and output side. However, we agree that as you move into the network input abstraction tends to increase. Until you hit the signifier divide, in which we switch perspectives to output abstraction. Our model then has output abstraction starting high and then decreasing as you journey closer to the output.
Both input and output abstraction measure the compression of information in the same way, it is simply that they are measuring different information channels. Output abstraction measures representations that affect the global output. This information channel generally expands towards the global output. Abstraction along this channel is measured similarly to input abstraction– though in an opposing way. Now it is the input which is the compressed point and the output which is the uncompressed point. We can thus count leaves along the global output… A.k.a. the external local output of an inout of interest.
Let B(Y_G) represent the total bandwidth of the global output.
Let Y1 represent the portion of the global output relevant to the abstraction X1.
We can consider the Compression Ratio as a metric for abstraction. Abstraction = Size of Compressed Data: Size of Uncompressed Data
A1 = B(X1) : B(Y1)
The addition of information and the increased bandwidth of the output does not happen on the neural level. Afterall, individual neurons have more input channels then output channels. Instead, the increased bandwidth happens on the macro level. This happens in multiple ways. We will discuss the two most relevant methods of increasing bandwidth here.
First, the neurons are linked in such a way so that as high order commands move to the global output, other information, generally from less abstract input side pathways, interact and get added to these commands. This adds the “on-the-ground-context” to the higher order commands. You can imagine the example of catching a ball. The command to catch the ball gets combined with spatial information relating to where a ball is in space. The less abstract information, often conveyed by fluidal structures gets combined to the higher command, and the bandwidth increases. This is often the role of the controller niche triggers. They take in information from higher control triggers and affect either lower control niche triggers or less abstract pathways of fluids. While each trigger individually tends to increase abstraction, the addition and combination of information on the macro scale continues the trend of decreasing abstraction towards the global output.
The second source of added information happens as the commands map to the final global output. Where the higher order commands finally affect actuators which deal with the external environment. Here there is often an increase in bandwidth that is in direct relation to the number of actuators and the complexity of their task. This added information can be considered “embodied” in the number and type of actuators. Commanding these actuators is how the network receives value from the measurement function. A well-developed control system is likely in place given sufficient training so that high-up output commands can be translated to functional and effective responses.
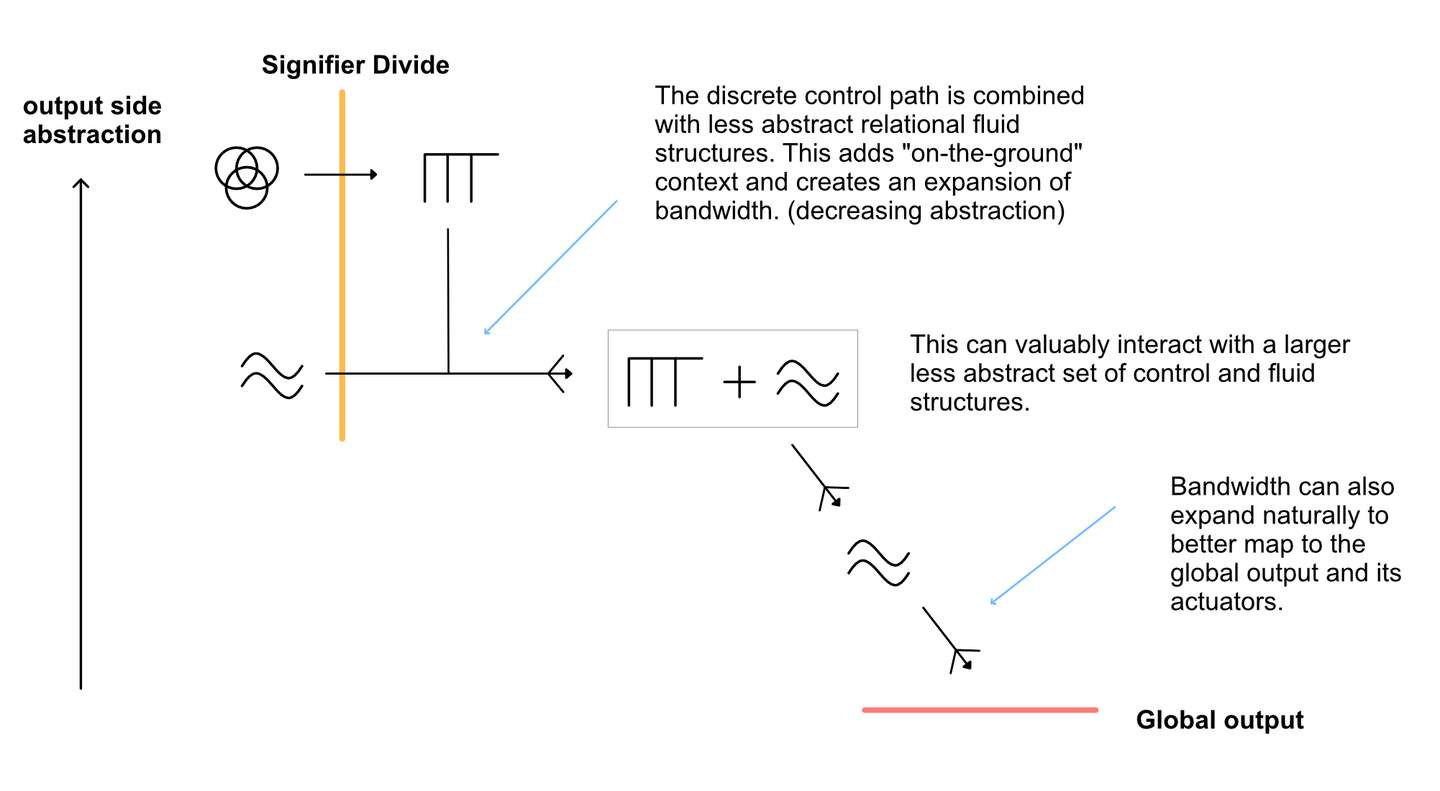
We also have invariance shifts on the output side. For example, in an image generative network we can imagine a neural inout that “commands” the generation of a face. This inout may not be connected to any spatial information. Instead, this information gets included later as the “command” reaches lower level inouts. Thus, the higher inout is invariant to the output space, while lower down response inouts are not.
However, invariance is different on the output side. On the input side we connected invariance to trigger structures filtering out irrelevant noise. But on the output side, the final output is not some pattern recognition to denoise, instead the final output is the global output. An inout that adds in spatial information can NOT be considered to have added noise. The spatial information is extremely valuable and relevant to the final output. Therefore, adding in spatial information or any other such information only even happens if it is valuable to the final output. This wouldn’t include real noise.
Note: Never say never! There are game theory games where the addition of noise is an effective behavioral strategy. Rock, paper, scissors for instance.
Do micro signifier divides exist?
Ok let’s add in the final curve ball. We discussed earlier how the switching of representational domains contributed to a new abstraction metric: output abstraction. This makes sense because now we are defining a different information channel representing a different thing. Then we wondered in a scary foreshadowing manner, could there be other times where we switch representational domains?
Well, here we argue yes. And the final niche within the trigger family exemplifies this argument: the framing niche. The framing niche we defined as “providing a signal with value as an external clue to affect other recognitions within the global input”. This is perhaps best understood with the below diagram.
The representation x* has been building pattern on top of pattern to form its recognition. However, those patterns and clues have all been “internal” to the greater representation. The framing niche offers valuable external clues that are not a part of the representation that they inform.
Consider the following example. Imagine an image recognition network. It is presented with an image of a face that is occluded and difficult to see. Each feature of the face is muddled. Regardless, one pathway builds pattern on pattern to recognize the face. Now that “face” abstract representation is connected to a “framing” niche neuron which sends feedback to lower feature representations. Now knowing that the image is of a face, the framing signal also allows the lower feature representations to recognize the eyes, ears, nose, etc. Now, imagine measuring the abstraction of those lower feature representations. We count the external local input. However, it was connected to the “higher” representation of the face! So… now the nose representation includes the external local input of the face representation?! If we were to treat framing signals as such, the abstraction metric in complex networks would be essentially useless as we would be following framing signals ever upward and constantly including more and more external local input.
We do not need to do that however as framing signals can easily be defined as a separate message. Consider that the patterns of the nostrils, and the shadow of the nose bridge all can be defined as internal representative clues to the nose representation. While the face representation is an external clue, an external message in relation to the nose representation. One that we can treat differently.
However, once we treat this message as different… we run into a new problem. How does this relate to abstraction? Let us consider how this relates to the signifier divide.
Remember way back to our initial discussion of the signifier divide. It is defined by a division between two representational messages. The recognition messages, based on the global input, and the response messages, based on the global output: “If x then y”.
Our deductions from our general learning network model indicated that such a divide existed, however it could not specify where. We then pursued a different argument derived around modularization of behaviors. We argued that different input situations often valuably utilized the same or similar behaviors. We then came to this conclusion:
“The value of the representation is the subtle key here. If the value of the representation is derived from the affect it causes it should be considered a “Y”, a representation of a responsive behavior. If the value of the representation is derived from selective recognition of the situation, then it should be considered a “X”, a representation of a recognized pattern of inputs. This division is not easy to find, and may not be discrete, however behavior modularization gives us clues.”
With the framing niche we can see something like this. Where the inputs of the inout are representations based on the global input (as we expect). However, the output of the neural inout is defined not by the global input, but instead by its effect on other input-side representations. It is, in a way, more closely related to the response niche because its output is better defined by the behavior it produces. The “value of the representation” is directly derived from the affect it causes.
One can conceive of inouts within the framing niche that are not triggers, a detector sending a single external clue signal for example. However, we consider framing niche inouts to often be trigger structures because the framing value is closely related to the output response. If the output response is valuable in multiple input situations, then indeed we expect a trigger structure. In such a case we have behavioral modularization within the input side of the network.
Thus, we have the following two conclusions.
The framing niche can be considered to be valuable due to a new sort of representational message, one that is external to the representation being made.
The framing niche’s valuable message can be considered as a valuable “response” that affects other representations on the input side.
Together these conclusions point to the idea that we can consider the framing niche to create micro signifier divides.
The regulation niche.
The framing niche is not the only niche in which this phenomenon may be observed. A observant reader may have noticed we skipped right over the detector structure’s regulation niche. We did this for a reason. The regulation niche can be argued to be an example of the micro signifier divide on the response side of the global network.
The regulation niche is defined by signals which valuably change behavior based not on the global input, but instead based on internal behavioral output conditions. This is generally done by a detector recognizing specific combinations of patterns in output decisions.
Like the framing niche, the defining valuable signal of the regulation niche can be defined as a separate “message”.
Other response niche inouts derive value from receiving signals from the input side and coordinating behavior within the global output. Generally, they receive signals to do “y” or adjust “y” which the output of these inouts then act out. With fluid structures these are continuous signals, with trigger inouts these are more discrete signals. Often you can describe the input side of these inouts as acting upon combinations of signals, however in this case they do not selectively filter out situations. The selective filtering was all performed on the input side. Instead, they simply causationally act dependent on the input signals provided.
Regulatory niche inouts are different, however. They DO selectively filter out situations. They DO act in a similar way as recognition inouts on the input side of the network. Regulatory niche inouts detect combinations of output responses while utilizing their non-linearity, and thus filter out situational inputs. They act more like an “If X”.
This is not a massive representational domain switch like that from input-based representations to output-based representations. Instead, this representational domain switch is more subtle. Other messages within the output side essentially represent valuable behavior based on external X input situation. Regulation niche output message however represent valuable behavior based on internal Y conditions.
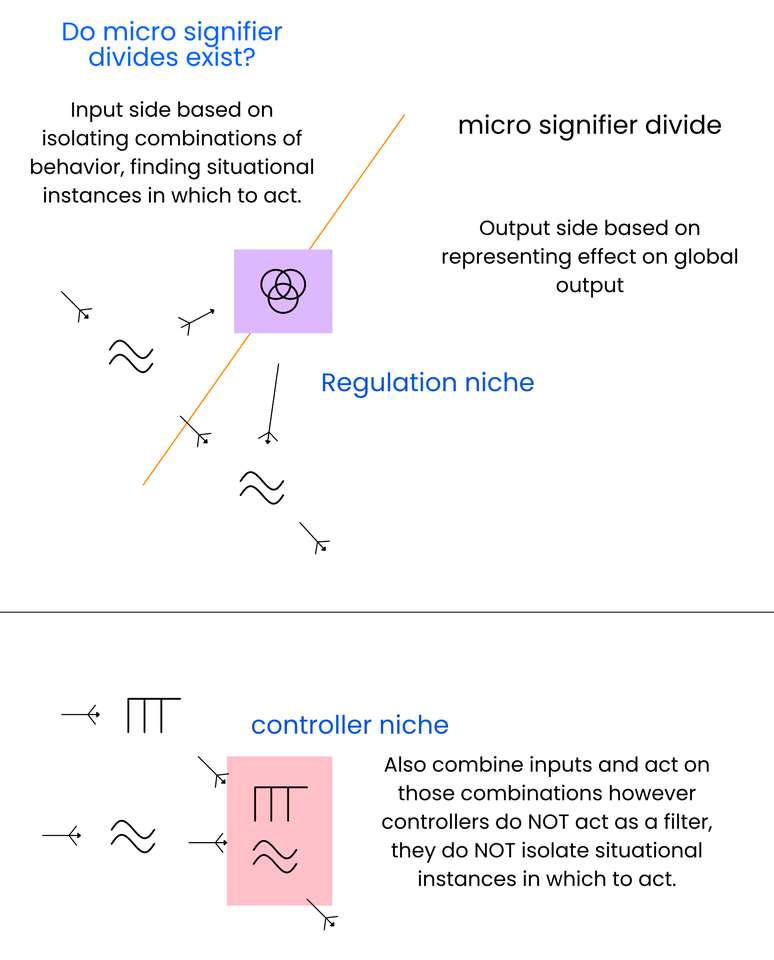
Notice that with the framing niche, the micro-signifier divide was based on a message whose value is derived from a set response. This stood out against the input-side backdrop of recognition inouts whose value is derived from selective filtering. Then notice that with the regulatory niche, the micro-signifier divide was based on a message whose value was derived from selective filtering. This stood out against the output-side backdrop of response inouts whose value is derived from set response. In the two different contexts the micro signifier divide can be identified by inout’s who derives value in a different manner to the other inouts that surround them. As is often the case with our general learning network model, there is a curious symmetry between the input and output side.

It’s important to note that the representational domains of the macro signifier divide still take precedence. The representations from the framing niche still inform on the global input. The representations from the regulation niche still produce changes in the global output. The micro signifier divides define representational domains within that macro context. Notice also that it was causational specialization which created these micro signifier divides just as was the case with the macro.
Measuring abstraction through the complexity.
At the beginning of this chapter abstraction looked conceptually simple: Find a representative inout and measure the leaves of its symbolic tree. Find its external local input. This would give us the compression factor of the representative message. However, we quickly found problems with this simplistic view.
We found that abstraction is relative to the representation/ message that we are considering. If the message is representative of the output side, we need to recontextualize abstraction. We need to measure the symbolic tree that reaches towards the global output. The compression factor in this case is based on the external local output of the inout of interest.
We also found that the filtering out of noise does not increase abstraction. Therefore, the trigger structures invariance niche must be considered separately. While the invariance niche does filters out information, that information is not relevant to the final message, and so ‘selective’ compression did not occur.
Finally, we had the major curveball. We found that you can argue for new representational domains within the input and output side of the network. New representative domains which have their own messages that could be considered separately. On the input side, these new representative domains revolve around messages whose value is derived from a set altering of other input side representations. It’s a valuable responsive change to the input side that can be utilized in multiple situations. On the output side, these new representative domains revolve around isolating new situations based on the set of “orders” given. It’s a valuable isolation of situations where combinations of orders can be valuably acted upon.
Given all of this complexity, what does this mean for measuring abstraction? Is it actually possible? Wouldn’t we need to know what each inout represents beforehand? If so, wouldn’t that render the entire exercise moot? These are questions that deserves much thought. Unfortunately, to delve into it in depth is out of scope.
We will, however, provide some foggy thoughts on the issue. Foggy meaning: we believe there are factors that have not clearly presented themselves and many details need to be worked through.
First, we would need to find the Macro signifier divide. We will discuss methods of doing this in the final chapter of this essay. We believe this is possible though with a degree of uncertainty.
Given that we know approximately where the macro-signifier divide is, we know whether a neural inout i is within the input or output side of the network and we can act accordingly.
-
We may be able to identify micro-signifier divides via combining multiple clues.
Many framing niche inouts will cause a massive jump in external local input.
There may be a way (input attribution methods)to find the pathways that constitute the representation of internal patterns to the inout of interest.
Framing niche inouts will often be triggers.
-
We may be able to identify invariance niche triggers via multiple clues.
Identifying that the neural inout is a trigger structure.
Identifying that disconnected input situations define a dimension of noise. This could be done via input attribution methods.
Regardless we could ignore invariance triggers affect on abstraction measurement via averaging the number of external local input/output over a number of training examples.
We could use invariance triggers as landmark strata lines within the network, and measure abstraction from these landmark strata lines, instead of from the global input/output. This would allow higher order representations to be measured via a unit of representation that is closer in type. For example, measuring a neuron that represents “justice” via the number of external local inputs could be a considered a mismatch of type.
In general, we believe measuring abstraction of a representation is possible and that we can account for the kinks introduced in this chapter. The main difficulty is of course, figuring out what different neural inouts represent. However, this does not need to be an absolute solution. We can slowly work our way forward via combining clues. For example, identifying invariance triggers may not require understanding the exact representation, but instead identifying a relationship between the trigger’s input representations. We believe that many such step-by-step clues algorithmically implemented and cross validated in a sudoku like manner, can lead us to interpretable metrics and representations. But much work needs to be done.
9. Symbolic growth hypothesis
We likely er in this chapter more than in any other. But to er is important in finding the truth. Here, we model the relationship between neural structures, neural growth, and the representations they form. We do so in detail and given such detail, we present many fronts and opportunities for error. However, we hope these details and the errors they create, fuel better questions and better further work. Anyways, onwards.
There is a seemingly problematic paradox when considering symbolic growth within our general model of learning networks. Every update step moves in a “valuable” direction, but both input-side and output-side symbolic structures are essential for optimizing the measurement function. This leads to a co-evolutionary symbolic growth problem: an input-side symbolic structure gains value only when linked to an effective output-side response, and vice versa.
To elucidate, consider a simplistic example involving an ant's neural structures. An input symbolic structure recognizing a 'large moving thing' would only gain value if linked to an effective output response, such as 'freeze.' Absent this connection, the input symbolic structure would lack value and thus would never be refined or retained, barring random coincidence.
This is an interesting paradox: the input and output side need each other like two sides of a coin. Thus each valuable step in input-to-output mapping development seems to require a simultaneous change on both sides. An input-side symbolic structure must maintain a direct linkage to an output-side response for its sustained value and refinement.
Let’s consider our ant improving upon its mapping. The ant currently has an input to output mapping, where recognizing a “large moving thing” is connected to the response “freeze”. To increase the fidelity of these representations, a new valuable path with its own recognition and response must emerge. Perhaps the ant starts to recognize not just a 'large moving thing' but also its increasing size (indicating that the thing is approaching). This new recognition only gains value if linked to a corresponding change in the ant's behavior, such as 'run away’. Thus somehow the input side and the output side has to simultaneously grow.
This co-evolutionary symbolic growth problem is quite the riddle. How do input side and output side symbols grow when they need the other to be valuable. The answer to this conundrum is to reconceptualize growth patterns. Pathways within neural networks do not so much “grow” as they “refine”.
In this chapter we present a hypothesis for how early growth patterns of symbols work. We suggest that the pattern is exemplified by a multi-paradigm sequence where different internal conditions are valuable to the loss function. These paradigms are not mutually exclusive, and different parts of the network will be at different stages at different times. Essentially this growth pattern boils down to pick the “low-hanging fruit” first. The easiest way to improve the measurement function is likely the first to be found - given the current state of the network and the update signal.
Value in robustness
Imagine the early stages of a Learning Network learning. It has inputs streaming in from each input situation it encounters. Its internal processing is not refined. Different inputs are not yet correlated, no valuable fluid transformations or detections or triggers are taking place.
Valuable connections begin to be refined by the measurement function. These are rudimentary input-to-output linkages that, although imprecise, enhance the network's performance slightly. You should imagine valuable little kinks in a generally terrible input-to-output mapping.
Importantly the network has a lot of noise. Both internal and external noise. Internal noise being the noise generated by a poorly tuned network, and external noise being the information from the global input that the network has not yet learned to ignore. This results in a robustness, because these simple, imprecise, but valuable kinks can be valuably learned over and over again in different noise contexts.
Many of the rudimentary input-to-output linkages become robust along specific dimensions. Two important dimensions stand out: the input space and the output space. The input space and the output space are structured by the relationships between the sensors and actuators respectively. For example, an image recognition network has spatial relationships between its pixel-based input, in that neighboring pixels are more related than further apart pixels. These are exceedingly important dimensions early in the network’s training because constant relationships exist within them. Constant relationships that have a steady feedback signal and that can be learned and exploited.
Value in rudimentary fluid mappings between input and output
The network refines those areas of the input-output transformation which are generally applicable to most situations. This is because common situations provide more training data and thus more update signal.
The most common valuable relationships for the fluid to model are once again the input space relationships and the output space relationships and connections between them. For models with spatial inputs, that means finding that spatially nearby inputs channels are related, and that this relation can sometimes affect the output. For models with temporal sequences as output that means finding that neighboring output channels in time are related. Simple localized heuristic rules based on these relationships provide easy to capture value.
This eventually forms into a rudimentary transformation from input space to output space made up mostly of fluid structures. This fluid structure is extremely high dimensional. But that does not mean that those dimensions are being utilized effectively. It is high dimensional because it is comprised of many robust and redundant pathways. It is high dimensional because generalization is still extremely low.
This pathway being made up of fluid structures, is continuous in nature and responds effectively to the continuous gradient presented via backpropagation. Parameters on mass alter along the gradient.
Input to output mapping improves. But no single neuron is directing large change. Certain input signals are causing localized changes to output responses. Localized here meaning local in input space and output space. So that the same valuable kinks/mappings are being figured out along the input and output space dimensions.
But that is not all. The input to output mapping is also localized to different situational inputs. In other words, the external and local noise means that inouts in the same “space” will valuably respond to different “input ranges” even when this could be easily modeled by less parameters. Inout i and inout j can find value producing the same output given different input conditions, even though one inout could perform both roles. The noise of the network makes such redundancies hard to find. This is a simplified example, but we expect such situations to be common early in training, as many inouts refine in similar directions given the update signal.
Abstraction at this time is generally defined by the macro structure of the network. That is because the fluid pathway is defined by the dimensionality of the input space, the multitude of neurons that have found a semblance of value during the robustness era, and the dimensionality of the output space. Within those bounds they are tangled mess slowly forming into an equivariant transformation. No intelligent filtering and selection of patterns are happening here yet.
There are situations, such as with categorical encoders, where the input space is high dimensional and the output space is low dimensional, and so the input-to-output fluid pathway is naturally high in abstraction. But high in abstraction does not always mean capable. Such a categorical encoder in the early stages of training is an example where lots of information is being filtered… it just not being filtered well.
Initial niche winners and the rise of generality.
Redundant pathways along input space and output space are not truly redundant. They simply service different localized areas within the greater transformation. Redundancy along situational input dimensions are truly redundant. For example, neural inout i and neural inout j producing the same output given different inputs, even when a single neural inout could perform that role by inputting both input signals.
As input-to-output mapping improves, the network slowly figures out which inputs to listen to. This drastically decreases external noise. The new input environment helps choose winners and losers. Certain redundant inouts through some slight competitive advantage, got more update signal, and thus further refined by backpropagation. This snowballs until they fill their niche much better than other redundant connections. They slowly capture the situational input sets of their redundant rivals.
However, this is an interconnected network. Different inouts are connected to each other throughout the input to output mapping process. The competitions to define niche winners upstream affect the inouts downstream and vice versa. Changes beget turbulent changes.
The losers of this game are not, however, finished. These pathways and neurons did not lose their connections; their initial redundant role has interconnected them with the greater input to output mapping. The specifics of their interconnection provides them with new opportunities to specialize. Often working with the neuron which supplanted their original role. The losers thus start specializing again in some different way, and once again, many of them are redundantly pursuing the same specialization with slightly different situational input sets.
It is difficult here to not metaphorically consider our own economy. Think for instance of the tens of thousands of projects currently pursuing artificial intelligence solutions. Many of these solutions are redundant. Only a few will capture a niche of value.
As with our economy, the old ‘game’ to capture value opens up and contextualizes the new ‘game’ to capture value. For example, the computing and internet era created much of the infrastructure that this new AI wave relies on. One should imagine similar occurrences within neural network niches. Where the winners of past competitions provide useful signals that can be utilized by new inouts.
Discrete beginnings
The neural network’s representational structure at this point still looks like a massively high-dimensional continuous transformation from input-space to output-space. Many neurons are finding their niche representing dimensions within this fluid transformation. These have captured or are capturing applicable situational sets. Others, however, are caught with no established valuable role. But they do have a position within the network, with inputs and outputs connected, ready to capture new opportunities that present themselves.
The mapping is still very localized in input space and output space. If the loss function calls for some big change across all localities of output space the mapping struggles. High level coordination across the mapping would be valuable, but such coordination does not spontaneously appear, it needs to grow from the mapping as it is.
Within this fluid transformation, some neurons start displaying discrete features. These are the first neurons moving in the direction of detector archetypes and trigger archetypes. The key word there was “within” the fluid transformation. These neurons lost the fight for the initial continuous niches but still retain their connections. As they begin to detect or trigger “things” they do so from within the context of their placement within the fluid transformation. These detections and triggers are extremely local.
We hypothesize that the initial role of these discrete neural inouts is to better clarify the edges and boundaries of decisionary splits within the fluid transformation. A decisionary split is when different ranges of input calls for different output reactions. Because all neurons are currently fluid structures these splits are not really splits but a continuous branching. Imagine a split in a walking path heading in two different directions BUT many people ignore this and so continue to walk in-between the split. Discrete inouts start providing true divisions and enforce that no one walks on the lawn.
However discrete inouts cannot do this at abstract levels yet. There are no pattern recognitions or controls built up. Instead, the detector and trigger archetypes need to find a place within the current infrastructure. We suggest the first initial discrete neurons emerge throughout the continuous transformation mapping and that their output feeds back into that transformation. They help shape the transformations decisionary splits wherever they can, from their extremely local and relational positions.
Discrete building on discrete
Discrete neural inouts can be imagined as somewhat “above the fray”.
The fluid neural structures are constantly impacting each other in a contextual web, conveying relational data, noise, and non-committal information. They are a part of a larger structure born from robustness whose form is constantly evolving given training.
Discrete neural inouts, on the other hand, take their input data and pronounce a detection or a trigger. They are, in a sense, more reliable, and more certain. However, this competitive advantage means much less when they are reliant on layer and layer of continuous transformation. In such a case their “more certain pronouncement” is built on a house of sand.
Thus, while initial discrete neurons may find niches throughout the continuous transformation, the areas of greatest impact are at the beginning and the end of the network. At the beginning, detector archetypes can find a place recognizing consistent input patterns. At the end of the network, trigger archetypes can find a place producing consistent output behavior. Keep in mind because of the nature of the continuous transformation, these initial detectors are extremely localized within the transformation’s representation of input and output space.
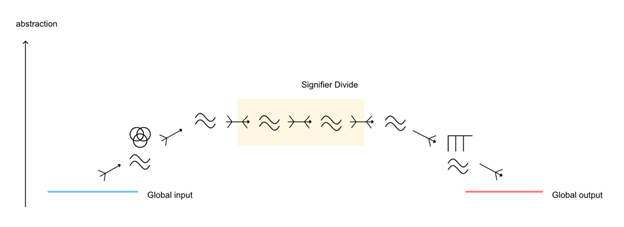
Once established at these two ends, the existence of these discrete neurons creates further opportunity. New discrete neurons can build on top of the old discrete neurons. At the beginning of the network, higher order pattern detectors build up on top of earlier detectors, triggers find a place filtering out noise and creating invariancies. At the end of the network higher order triggers build on top of earlier triggers, so that now more complex behavior can be created consistently.
This pattern of discrete structures building on discrete structures increases abstraction. This correlates with a “zooming out” of the localized area of interest within input space and output space. This has yet another niche advantage in coordination over larger areas of input and output space.
Because the discrete structure growth pattern is to start on both ends of the network and grow inwards, a fully discrete pathway is one of the last things that emerges, if it does at all. The input-side discrete structures do not initially gain value by directly affecting the output-side discrete structures. Instead, the input side discrete structures feed back into the continuous fluid transformation and help it. They gain value by structuring this fluid transformation, and it is this fluid transformation that directly affects the output-side discrete structures.
New niches
The first discrete structures were contextualized early within the continuous transformation. Each subsequent discrete structure incorporates more data from the input or output space. This zooming out leads to representations that are not as localized.
These less localized representations then feed back into the continuous transformation. This provides new opportunities within the continuous transformation. Now new fluid structures can relationally model the relationships between these higher order patterns.
Let us consider an example. Imagine our network has built discrete recognitions of the nose, eyes, mouth, etc. In doing so new fluid connections can start modeling the relationships between these detections. The eyes should be approximately this far apart within this range of variation, which looks different depending on the angle of the face, etc. These are high dimensional relationships between abstract detected patterns.
Ahh but it does not end there. Notice that now these high dimensional relationships can be utilized to create new discrete representations. A particular set of variation, the eyes being this far apart, the nose being here and with this shape, etc. can be utilized to make discrete recognitions of individuals.
This in turn may introduce new continuous niches, say modelling the relationships between individuals. This will continue to happen as long as further abstract relationships are valuable to model so that the network improves its mapping from input to output.
Onward and upward
We hypothesize that this pattern of discrete building on discrete from the ends of the network inwards continues. Each time opening up new niches within the fluid transformation and better structuring and refining it. Each time allows for recognitions and responses that affect larger areas of the input and output space.
Let’s now focus on two questions. First, how does this growth pattern sidestep the co-evolutionary symbolic growth problem? And second, at what point does this growth pattern stop?
First the co-evolutionary problem. You will remember that the co-evolutionary symbolic growth problem described a seeming paradox where input-side recognitions found no value unless simultaneously linked with output side responses. The ant could not refine its concept of “big thing that moves” unless the refinement was simultaneously linked with a response.
Our symbolic growth hypothesis shows how this co-evolutionary problem may be solved. Generally, it is solved because of how the symbolic growth occurs. First a continuous and relational fluid transformation forms between input and output. Second, discrete recognitions and responses form out of this transformation in order to better shape the transformation.
If a discrete response suddenly forms on the output side, it is true it would need some input side decisionary split leading up to it. But in our symbolic growth model this input side decisionary split can form slowly as a part of the fluid transformation. We can imagine a slow continuous change towards the use of the discrete response, until perhaps that change develops into a discrete recognition.
In our model the recognition and the response starts as a part of the fluid structure. In our model, there is generally always some fluid continuous connection between inputs and outputs at all abstraction levels. The growth out of this continuous structure allows for an incremental back and forth that refines both.
When the network is more mature this incremental refinement becomes more powerful. That is because some of the fluid structure now models relationships between discrete structures on the input and output side. In this situation the continuous incremental back and forth can now utilize combinations of discrete recognitions and responses. Intelligent fluid combinations of connections between input recognitions and output responses opens up many possibilities.
The second question was at what point does this growth pattern stop? At what point do discrete structures stop growing from either end of this continuous fluid structure? One may be tempted to quickly answer “when the two discrete sides meet!” However, we do not believe this always happens. In many cases, we believe the discrete localized representations on the input side and the discrete localized response on the output side form a combinatorial “language” that the middle continuous transformation can readily utilize. In this situation, the network can memorize input to output responses without fully generalizing. This is, of course, a common problem with training neural networks. They overfit to the data and do not generalize.
Our symbolic growth pattern hypothesis would suggest that this happens when the following is true:
Input side discrete representations have formed and in combination create an effective recognition of the global input’s situational set. (As this recognition relates to the measurement function).
Output side discrete representations have formed and in combination create an effective response within the global output. (As this response relates to the measurement function).
The dimensionality of the continuous transformation is capable of modelling the combinatorial relationships between the input and output discrete representations effectively.
The input space and output space and their relationship to the training set and measurement function does not require global generalized understanding. Localized representations and communication between such representations can effectively meet the task.
Such a situation is difficult to break because the network is creating an effective input to output mapping. It is doing the job you asked it to do! It is just that the task you have set it, with the training set and the parameter count provided created this overfitting situation.
When the discrete meet
One may be tempted to see the meeting of the two discrete niches as some grand momentous occasion. Certainly, this was the author’s first naïve thought many years ago. But given consideration, we now do not think it is possible or wanted for the discrete to completely meet.
First, consider that as soon as the two discrete niches meet, the co-evolutionary problem takes full effect. The fluid structure was required to mediate adjustments. With only discrete structures, no future adjustments to that abstract pathway is possible.
Second, consider our previous point: that as soon as new discrete structures emerge, a new niche for fluid structures appears. A niche of modelling the discrete structures relationships within a relational context. This would imply that even if you did run into the situation where the discrete meet, it would be short lived. Quickly fluid structures would fill valuable niches around and in between them.
It is however possible that in some contexts, as representations get more and more abstract you see less and less fluid structures. This is because the relational context of highly abstract concepts can lose dimensionality as they relate to output response. The continuous prescription niche becomes less dimensional. For example, consider the high-abstract and low-abstract pathway for catch a ball. The high-abstract pathway needs to decide that this is a “catch the ball situation” and trigger a “catch the ball response”. That involves very abstract representations but the relationships between those representations is rather low-dimensional. Compare it to the low-abstract pathway. In the low-abstract pathway, the network needs to isolate the ball’s size, shape, and location within the input space, and coordinate a high dimensional set of movements to get the hand at the right place, time, and configuration in the output space. That is a high dimensional relationship between input and output representations.
Therefor we predict the signifier divide to be more “discrete-like” at higher levels of abstraction, and more “continuous” at lower levels of abstraction. Though this should not be considered a hard rule. It depends on the dimensionality and relationships between the input and output representations at that point of abstraction.
If you are searching for a grand moment. Perhaps where “generalization is achieved!” We would advise you to reframe. Embrace the complexity. There is no binary state of achievement, though we humans will certainly attempt to devise them. Instead, the input-to-output mapping will simply improve along the multi-dimensional training gradient until it hits a point. This point is related to the input and output conditions, the network’s fixed structure, and the learned structure. The learned structure which may or may not have found a local minimum that it can not escape. Moving this point back requires work on a series of fronts. It requires reorganization of recognitions and responses at multiple levels of abstraction. There is no binary state of achievement, only better organization of input to output mappings in relation to the measurement function.
10. Summary & Measurable Predictions.
Quick Summary
This paper has reframed the internals of neural networks. We have done so from two general models.
Our top-down model was a general model of learning networks. It can be described simply via the abbreviation INOMU. Where Input enters a Network to produce an Output which is Measured against some target state, as to create a signal which Updates the network. From this simple model of learning networks, we derived an internal meaning of value. An improvement to the mapping of inputs to outputs as qualitatively assessed by the measurement function. This definition of value was then deduced to also affect all internal inouts within the learning network. So that all change to smaller input-to-output mappings was also subject to a qualitative improvement of the measurement function. Given this, specialization results and we get niches of value.
We then deduced the existence of the signifier divide: Given a trained learning network without loops there is a division s in which representations prior to s are best represented in terms of the global input, and representations after s are best represented in terms of the global output. We call the division s the signifier divide. The signifier divide represents a split with common wisdom. Now we consider multiple abstraction metrics relevant to different representational messages. We then noted how the signifier divide is justified by and results in behavioral modularization. Where different situational inputs lead to the same output representations instead of creating their own specific output responses.
With the signifier divide we were able to define our top-down niches. We defined the representational niche and the helper niche. Our focus, being on the representational niche, further divided it into three categories. The recognition niche contains all inouts representing sets of variation within the global input. The response niche contains all inouts representing sets of variation within the global output. And the prescription niche which includes those inouts which bridge the gap between recognition and response.
Our bottom-up model was a model of representational units within neural networks. We found that structural units and representational units are different. Representational units are some input-to-output mapping that could include some of the parameters of neurons, all the parameters of a neuron and the parameters of groupings of neurons. To deal with this we defined an adjustable reference frame. An abstract grouping of parameters that can define any input-to-output mapping. We called this an inout. The flexible nature of inouts allowed us to define groupings of parameters which align with units of representation. A Representational inout is defined by an output which represents a defined set of variation that is differentiated from surrounding variation.
But how can we practically identify such representational inouts? Well in pursuit of an answer, we delved into the measurable differences between different neural and sub neural inouts. We found the following dimensions:
relational situational frequency of input channels (whether neural inputs fire together or fire separately in relation with the global input)
The neural input relationships with each other with respect to the neural output response (Are the neuron’s inputs complementary, alternatives, inhibitory, stand-alones, etc).
The change in output frequency, defined by taking the average of the inputs situational frequency and comparing those to the neural output’s situational frequency.
The situational frequency of input channels and the input channel relationships are high dimensional differences. These can take many forms and threaten overwhelming complexity. For our purposes we grossly simplified these into simple binary options. Are the inputs situationally co-occurrent? Do the inputs individually weakly impact the output, or do the inputs individually strongly impact the output?
We then found that isolating representative inout groupings, at least on a neural and sub-neural level, may be possible. First, we isolated the situational input groupings that are co-occurrent and that get activated in the training set. We then performed a look-ahead strategy to see if downstream neurons treat situationally disconnected outputs differently. If they don’t we can assume that the situationally disconnected input groupings are still connected under a single representative output meaning. This strategy has a few potential problems and so we also discussed a few rough heuristic methods of differentiating whether situationally disconnected outputs have different representative meanings.
Next came polar archetypal structures. These we defined by combining the extreme polar points on the simplified measurable dimensions we isolated. Many of these combinations were illogical or of no value, but the ones that were left created an interesting trichotomy.
Archetypal Fluid structure: has inputs that are situationally connected and that are low or high in influence. The structure has a constant change in output frequency. Whenever the inputs are affecting the neural inout in any way, the inout sends some sort of significant output. As inputs change, the output changes describing some useful continual mapping.
Archetypal Detection structure: has inputs that are situationally connected and low in influence. This inout also has a neuronal output frequency that is lower than the average output frequency of its inputs. This means it utilizes its nonlinearity to become somewhat sparse. Only specific combinations allows for significant neural output.
Archetypal Trigger structure: has inputs that are situationally disconnected and strongly influence the output of the neuron. Thus, the inputs tend to occur separately but if any input fires, it “triggers” the neuron. This naturally increases the neuronal output frequency when compared to the average output frequency of the inputs.
Given these structural forms we then hypothesized valuable functions that fit. We came up with a list of niches that we believed these structural forms may specialize in. We then contextualized these niches and forms within the greater context of the General Learning Network Model and the top-down niches. This gave us a map of the various niches of value. Now we have hypothetical niches of value, the niches potential location in the neural network, and the hypothetical neural structural form that fit into the niche.
At this point we may have been able to make our measurable predictions. However, a few questions still nagged. How do these structures work together? How do they form? How is abstraction involved? What does a mature input-to-output response look like?
Towards answering these questions, we embarked on studying multi-neural symbolic structures. Here we found a big difference between groupings of the continuous fluid structures, and the groupings of the more discrete detector and trigger structures. We could define a fluid symbolic structure by a representative set of neuronal output. Practically, this is currently unfeasible. Fluid structures relational mappings have an interconnected nature that makes them difficult. This difficultness extends to attribution studies and symbolic tree mapping. The discrete symbolic structures were much easier to deal with. We could choose a representative inout and consider a nice and clean symbolic tree leading to the global input or output. However, this was an idealized dream. We now know due to the symbolic growth hypothesis, that such discrete symbolic structures are very unlikely within neural networks, and that generally they would be encapsulated and contextualized by the difficult fluid structures. We finished this chapter by remarking that the signifier divide within the idealized discrete symbolic pathway would be discrete, not continuous. We mused that pathways that approach this idealized discrete dream would have a more discrete signifier divide than those that do not.
We then turned our attention to abstraction. Here we noted that measuring abstraction along the idealized discrete symbolic pathway would be easy. We would only need to count the leaves of the symbolic tree. But reality is messier. As previously noted, the fluid structure presents a mess of attribution. However, the true curveball came when we began to consider the trigger structure and its various niches relationship with abstraction. We found that the invariance niche can be considered to NOT increase abstraction because the dimension filtered could be considered noise. We then returned to the idea that the signifier divide creates two different abstraction metrics, and that the output abstraction metric should be considered separately. While input abstraction was about selectively filtering out information towards some refined valuable pattern recognition, output abstraction is about selectively adding information towards some larger response in terms of the actuators on the global output. Output abstraction is about adding ‘on-the-ground’ information and considerations.
Considering abstraction and the various niches presented one final surprise. We argued that certain niches create micro signifier divides which define semi-independent representational domains within the input and output side. These representational domains occurred via messages that juxtaposed their surrounding context. On the input side, the framing niche created messages that acted as external clues that informed on other representations. In some situations, these clues acted as a valuable set response worthy of behavioral modularization. This niche created a message with response-side attributes. On the output side, the regulation niche selectively filtered out situations based on output responses. This stood out against the backdrop of other niches responding to propagated orders originating from the input side. The regulation niche creates its own situational detection and thus creates a message with more recognition side attributes. These micro representational domains exist within the macro representational domains and were likewise defined by causational specialization.
Finally, we delved into the symbolic growth hypothesis. Here we clearly stated why we believe fluid structures are prevalent throughout neural networks. In order to learn, it seemed neural networks require a simultaneous improvement of both the input and output symbolic pathways. Fluid structures however allows for a refining, continuous learning environment that promotes incremental learning.
We then further explored our growth model. We found that the ever-changing environment of a learning network created substantial noise along multiple dimensions. In this regime robust and redundant pathways proliferated. However, as denoising slowly occurs, some pathways win their input-to-output “niche of value”. Out of this slowly refining fluid river, discrete symbols start to grow from the input and output side. These gain value in their certainty, and in their ability to better define the edges of decisionary splits. We then saw a back and forth growth pattern, where discrete symbols open up new niches for continuous relational context, which then opens up further niches for discrete symbols. This slowly builds more abstract pathways to the degree that abstraction and global coordination is valuable.
Measurable predictions:
Our final model has produced a series of predictions which are possibly measurable. These predictions assume:
Validating these predictions likely require alterations in interpretability software. These would generally be inline with the measurement procedures outlined in chapter 5: Measurable differences relating to neural representation. However, validating (and cross-validating) certain predictions would likely require greater advancements such as symbolic tree attribution and abstraction metrics.
After the presented list of measurable predictions, we will discuss the various difficulties which arise from using our particular model predictively. Generally, these issues arise out of the massive simplifications we have made. While these simplifications were extremely useful in creating this general base model, when applied to the real world, such simplifications create errors.
List of potentially measurable predictions
-
We aim to identify the macro signifier divide throughout applicable networks by looking for the following indicators. These indicators double as predictions:
We expect a marked decrease in the number of detector structures at the signifier divide. This marks the end of the recognition niche.
We expect final clusters of trigger style structures along input to output pathways to define the beginning of the response niche / output side of the network.
We expect that behavioral modularization has affected these structures so that situationally disconnected pathways converge on these structures.
We expect these structures to act on different levels of abstraction and along all pathways between input and output.
Any neuron behind these structures is predicted to represent behavioral responses better than they represent elements within the global input.
-
Given a defined signifier divide along different pathways, we can predict the constitution of neural structures within each side of the divide.
We predict that you can generally find all archetypical structures on both sides of a network.
The input side of the network generally has significantly more detector structures.
We expect fluid structures throughout the network contextualizing recognitions and responses within relational transformations that connects the input side to the output side.
These fluid structures will be found at all levels of abstraction.
We predict that many trigger structures can be found clumped relatively early within networks. These are within the invariance niche. They recognize the same pattern along a dimension of difference. This is done to remove that dimension of difference as noise.
We predict that after the clumping of invariance trigger structures, most networks have a scattering of invariance, grouping and framing niche trigger structures. These may be difficult to distinguish.
We predict that in some networks, particularly those with a high dimensional input and output space, the framing niche can become quite significant.
We predict that the next significant clumping of trigger structures are the controllers that help define the signifier divide.
We expect that any detector inout downstream of this signifier divide, represents a combination of output behavior and acts to either suppress certain outputs or add to the output behavior.

These predictions have a set of potential problems. After all, our model was based on multiple deductions, simplifications, and hypotheses.
If a deduction is wrong, we have a core problem with our model and we need a complete rework. This would be the case if a strong evidence or argument dismisses the concept of internal value, specialization, or the signifier divide. The signifier divide deduction is the most likely candidate for such problems to be found. We doubt a complete dismissal, though we would not be surprised by an improved rendering of the concept.
In this paper, we also made heavy use of simplifications. Simplifications by definition leave out information and so create to-some-degree an incorrect model of reality. The main simplifications of note were the massive simplifications made in our measurable differences. We took the high dimensional space of situational input frequencies and neural input relationships and converted them into binary variables. We then took these simplified variables and mixed and matched them to produce extreme archetypal structures. We were very clear that these structures defined the extreme forms along measurable dimensions. However now when considering measurement, we need to take these claims much more seriously.
What defines a trigger structure in reality? What defines a detector structure in reality? How do we define groupings of inputs which fire together? What thresholds do we use in the input space? What thresholds do we use to define a significant output? These questions and more will plague the verifier of our predictions. We do not believe such questions are unsurmountable. Though it is worth noting that in attempting to validate our predictions, the validator will likely come up with a more complex and compete model with less simplifications… which in turn will generate better predictions.
Finally, we made a series of hypotheses about valuable niches. These hypotheses were structured as to be grounded in value provided, the contextual placement within the neural network, and within the neural structures defined by the measurable dimensions. For example, we hypothesized the existence of the invariance niche, based on the value of denoising irrelevant dimensions, existing on the input side of the network, and based on the trigger archetypal structure.
Despite our efforts, these hypotheses may be wrong, or more likely, missing key details and refinements. There are three main expected issues here.
First, that the increased dimensionality of the measurable dimensions means that the specialized structures that fill the niches of value are less ‘extreme’ and ‘immediately apparent’. For example, there is a range of possibilities between a detector structure and a fluid structure.
Second, we will find that single neural inouts can truly provide value in many directions of value. This will make validating these value-based hypotheses more difficult. For example, our current model allows for a single neural inout that fills the pattern recognition niche, controller niche, and framing niche. That is true without taking into consideration the increased dimensionality of the measurable dimensions.
The third expected issue is that there are other unknown niches of value which utilize similar neural structures and placements and thus provide false positives. Such situations may mess with our measurable predictions.
We sincerely hope and encourage others to test our predictions. Where we are wrong, we shall learn, where we are right, we shall jump up and down. Regardless there shall be a further opening of more nuanced and specific questions and answers. The opening of one representational niche begets more.
The amount of current research on artificial intelligence is mind boggling. I predict this to only continue. In my data science master’s degree, I would often choose a topic, only to find a few weeks later that someone just published a paper on that exact idea. It was a rat race. To get my degree, I needed to publish, in order to publish I was told I needed to beat some established benchmark. Everyone was racing to optimize measurable goals.
In this context, certain types of ideas were naturally demoted. First and foremost, theoretical explorations (like the one conducted here). Such explorations did not improve benchmarks. In data science, data is king. I understand and respect this… to the degree that it is useful. It is important to understand however, that some questions require zooming out. Some questions require theoretical modelling. Such discussions produce abstract ideas and concepts that cannot be reached any other way.
In this paper, we presented no data. Instead, we built two general models from general principles and then made a series of deductions. These deductions then combined to create a larger predictive model. This predictive model was grounded by keeping our discussion revolving around how we would perform measurements if we could.
Economics, my initial area of study, was full of this zoomed-out top-down modelling. But in the field of artificial intelligence, I honestly have no idea how such a work will be received. In my defense, I will remind the reader that physics began as theoretical modelling with insufficient data.
I consider the dislike for top-down theoretical modeling dangerous. Today, a different rat race is playing out. One far more threatening. There are multiple companies and countries now pursuing powerful general optimizers. While the large language models of today are sufficiently tame, agentic optimizers of tomorrow may not be.
Unfortunately, there is no data about such a future. We cannot collect data and build bottom-up predictive models. The dimensionality is too high. The system is too complex. Uncertainty is the rule in such a domain.
If we were, however, to attempt to model such a future, to attempt to see the risks and rewards, our best option is top-down theoretical modelling. To build simple general models and to make a series of deductions based on those models and their interactions. We should respect such predictions as our best clues, while simultaneously being skeptical of them. This is the nature of prediction within such an uncertain domain.
Given this, here is a simple model that has been proposed:
We are building more and more powerful general optimizers.
We can only set measurable goals.
-
A more general optimizer in pursuit of its goal will:
Optimize its goal ad infinitum.
Dislike changing its goal.
-
Pursue instrumental goals.
Money
Power
Greater intelligence
Self-improvement etc.
Unaligned over optimization is no joke. Drug addiction is an unaligned over-optimization problem. Cancer is an unaligned over-optimization problem. Corruption is an unaligned over-optimization problem.
Now I believe we can solve this problem. But let us not take it lightly. Things get messy before they get perfect, and the messy powerful general optimizer is likely dangerous. Let us learn from those who deal with uncertain, dangerous situations. Let us learn from firefighters, policemen, and the military. When addressing an uncertain environment with potential risks: slow is smooth, smooth is fast. When addressing general optimizers, we need to move smooth. Consider the alternatives. Implement multiple backup plans. Address concerns with more than a waving of hands.
In this paper we theorized how representations within neural networks form and are organized. We came up with a series of measurements which we believe best describe representative inout mappings. We hope future work will build upon this. We hope future work will allow us humans to look inside artificial neural networks and see exactly what they are optimizing for.
This would be the goal representation niche. A niche whose value is derived by internally representing the perceived goal of the measurement function. This niche is valuable because the network can simulate methods of receiving rewards, and thus improve the input-to-output mapping. With no loops, we do not believe that such a goal representation niche exists. Instead, the network simply produces effective input-to-output mappings based on the measurement function. However, with loops and various other necessities, this goal representation niche does arise.
Isolating, understanding, and isolating this goal representation niche is an important goal and steppingstone. In such a future we can focus on internal goals, not just the external measurement function. In such a future, may be able to start pursuing abstract goals, not just measurable ones. We may be able to say: “optimize general human happiness” or “design a city that would best accommodate human needs” or “figure out the best way into space given a set of unknown constraints”. However, the trials do not end there. Even such abstract goals have absurd extremes and potential nasty twists.
Sooner or later, we will start building these overly powerful general optimizers. Sooner I believe rather than later. Part of me yearns for us to stop, though I do not think that is possible. Therefor we must begin preparing. Currently I believe we are rushing towards agents that optimize narrow goals. The risk here is that such an agent begins a self-improvement feedback loop and becomes exceedingly powerful. It improves its inputs: gains access to various forms of data. It improves its outputs: It gains behavioral abilities via manipulation and robots. And it best maps inputs-to-outputs towards whatever goal it is aiming towards. It is unknown exactly how likely this risk is given the various conditions in play. Regardless the risk/reward is (very) high.
If such an agent emerges, it is my estimation that some internal goals are much worse than others. Narrow goals being generally worse than broader ones. Though complexity is the rule here, various conditions are important. Generally, we want an internal goal that has checks and balances. No other method has long term assurances.
With access to the goal representation niche, we may be able to embed sanity checks. We may be able to embed the understanding that pursuing a goal to the extreme is a bad idea. We may be able to embed the understanding that there is a greater more abstract goal that is much harder to define. We may be able to embed “do onto others (with different objectives) as you would have them do to you.” We may be able to embed a Shepards mentality and a wish to keep objective ecosystems in balance.
It is my estimation that the safest and most prosperous route is to embed wisdom into our Artificial Intelligences. Let us aim there. We want angels, not devils.
References
Bricken, et al., "Towards Monosemanticity: Decomposing Language Models With Dictionary Learning", Transformer Circuits Thread, 2023.
Elhage, et al., "Toy Models of Superposition", Transformer Circuits Thread, 2022.
Goh, et al., "Multimodal Neurons in Artificial Neural Networks", Distill, 2021.
Olah, et al., "Naturally Occurring Equivariance in Neural Networks", Distill, 2020.
Schubert, et al., "High-Low Frequency Detectors", Distill, 2021.
Olah, et al., "The Building Blocks of Interpretability", Distill, 2018.
Olah, et al., "Zoom In: An Introduction to Circuits", Distill, 2020.
Olah, et al., "An Overview of Early Vision in InceptionV1", Distill, 2020.
Cammarata, et al., "Curve Detectors", Distill, 2020.
Cammarata, et al., "Curve Circuits", Distill, 2021.
Olah, et al., "Feature Visualization", Distill, 2017.
Multifaceted feature visualization: Uncovering the different types of features learned by each neuron in deep neural networks Nguyen, A., Yosinski, J. and Clune, J., 2016. arXiv preprint arXiv:1602.03616.
Visualizing and understanding recurrent networks [PDF] Karpathy, A., Johnson, J. and Fei-Fei, L., 2015. arXiv preprint arXiv:1506.02078.
Visualizing higher-layer features of a deep network [PDF] Erhan, D., Bengio, Y., Courville, A. and Vincent, P., 2009. University of Montreal, Vol 1341, pp. 3.
Li, X., Xiong, H., Li, X., Wu, X., Zhang, X., Liu, J., Bian, J. and Dou, D. (2022). Interpretable deep learning: interpretation, interpretability, trustworthiness, and beyond. Knowledge and Information Systems, 64(12), pp.3197–3234. Doi: HTTPs://doi.org/10.1007/s10115-022-01756-8.
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “Why should I trust you?”: Explaining the predictions of any classifier. In Balaji Krishnapuram, Mohak Shah, Alexander J. Smola, Charu C. Aggarwal, Dou Shen, and Rajeev Rastogi, editors, Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13-17, 2016, pages 1135–1144. ACM, 2016.
Marco T´ulio Ribeiro, Sameer Singh, and Carlos Guestrin. Anchors: High-precision modelagnostic explanations. In Sheila A. McIlraith and Kilian Q. Weinberger, editors, Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, pages 1527–1535. AAAI Press, 2018.
Scott M. Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett, editors, Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 4765–4774, 2017.
Vitali Petsiuk, Abir Das, and Kate Saenko. RISE: randomized input sampling for explanation of black-box models. In British Machine Vision Conference 2018, BMVC 2018, Newcastle, UK, September 3-6, 2018, page 151. BMVA Press, 2018.
Gregory Plumb, Denali Molitor, and Ameet Talwalkar. Model agnostic supervised local explanations. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicol`o Cesa-Bianchi, and Roman Garnett, editors, Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montreal, Canada, pages 2520–2529, 2018.
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through propagating activation differences. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, volume 70 of Proceedings of Machine Learning Research, pages 3145–3153. PMLR, 2017.
Suraj Srinivas and Fran¸cois Fleuret. Full-gradient representation for neural network visualization. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’AlcheBuc, Emily B. Fox, and Roman Garnett, editors, Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 4126–4135, 2019.
Sebastian Bach, Alexander Binder, Gregoire Montavon, Frederick Klauschen, Klaus Robert Muller, and Wojciech Samek. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PloS one, 2015.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In Yoshua Bengio and Yann LeCun, editors, International Conference on Learning Representations, 2015.
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian J. Goodfellow, Moritz Hardt, and Been Kim. Sanity checks for saliency maps. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolo Cesa-Bianchi, and Roman Garnett, editors, Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montreal, Canada, pages 9525–9536, 2018.
Tingyi Yuan, Xuhong Li, Haoyi Xiong, Hui Cao, and Dejing Dou. Explaining information flow inside vision transformers using markov chain. In Neural Information Processing Systems XAI4Debugging Workshop, 2021
Appendix
Midflip context
The author is currently building a crowd sourcing website called: midflip.io. We utilize King-Of-The-Hill texts and Liquid democracy to build crowd sourced documents. It is a young venture with a bold vision. We aim towards innovation in collaboration. We welcome the reader to join our little experiment. Let’s build a social media that makes big groups smarter.
RepLeStruct Diagrams
The diagrams utilized in this paper are called RepLeStruct diagrams – Representing Learned Structures Diagrams. They are an attempt to visualize the various niches of value within a neural network. In representing such a complex domain, they necessarily simplify and that simplification creates a degree of inaccuracy. In this appendix entry, we will describe the diagrams, what they represent and the errors they produce.
RepLeStruct diagrams generally depict the findings and predictions within this paper. They utilize abstraction as a y-axis, and along the x-axis is a causational flow from global input to global output. This means that as you move up and rightwards, you are moving upwards in abstraction and towards the global output.
The different symbols indicate the proposed polar archetypal neural structures: the fluid, detector, and trigger structures. The arrow-based relationships between these symbols indicate general causation, and a general compression vs. decompression of information. This of course hides much information. In reality, neural networks are composed of tons of different neurons all with different structures. The mapping describes a general proposed idea of what types of structures you would find where and why.
We often show the fluid structure under a detector or trigger structure. This is to express that the detector or trigger is encapsulated within the fluid’s relational context. This is slightly misinforming. We hypothesize that detectors and triggers are always “somewhat” encapsulated within a fluid’s relational context. However, at lower abstraction levels, we believe this to be ‘more so’. Regardless at every layer of a neural network and at all abstraction levels you are likely to find every archetypal structure, only the concentrations may change with context.
The truth is that every architecture is different and that such idiosyncrasies would alter the expectations on the network. RepLeStruct diagrams attempt to remain general, though one can imagine how different networks would alter the visualization. Categorical encoders would have no output side. Gan generators would have no input side. LLM transformers would have massive, interconnected framing niche neurons etc.
Contextual information for isolating representatives inout groupings.
In part 5. Measurable differences relating to neural representation we described a method for distinguishing whether situationally disconnected outputs represent the same thing. We considered a look ahead strategy, where we looked to see if the downstream neuron treated the output differently depending on the situational context.
We also noted that heuristics may be employed to better identify situationally disconnected input groupings that have the same representative output. We said:
Combinatorial nature of input groupings.
Limited Number of situationally Connected Groupings
Contextual information
We did not, however, elaborate on point 3 because we did not yet have the relevant prior knowledge. Let us do so now.
Given our predicted niches of value we can see contextual placements within the neural network where disconnected input groupings are more likely to have the same output meaning. Namely within the invariance niche, framing niche, grouping niche, and the controller niche. Essentially everywhere we predict archetypal trigger structures to proliferate.
We may then add a slight bias towards predicting disconnected situational input groupings lead to the same output representation, wherever we predict trigger structures. Essentially, early in the network where we expect invariance triggers and along the signifier divide. These two spots are expected to have a larger concentration of triggers compared to the rest of the network.
Symbolic growth in the GRN.
While the co-evolutionary problem exists in all learning networks, the solution may be different. As we have noted, the GRN seems to be closer to the discrete archetypal pathway than neural networks. Here, for example, the solution to the co-evolutionary problem is likely different. The GRN has individual quirks and changes evaluated against the environment, which on mass results in a population-level update. I.e. evolution. This results in two tricks. First, a common mutation involves copying sections of DNA. This creates areas of redundancy that can adjust and specialize into a new but similar input-to-output mapping. Two, while the input-to-output mapping of DNA to protein is quite discrete, ie. Produce this protein or do not produce this protein. The number of proteins within the cellular environment, mixed with all the other proteins, starts to approximate a continuous system. This means that the gates which decide when to produce such-n-such protein, while seemingly discrete, may be considered based more on the probability that such-n-such protein is going to come in and trigger the gate. This mimicked continuousness likely allows for smaller continuous adjustments than the “discrete” gates would have you believe.





Hot comments
about anything